
Abstract
The aim of this project was to identify candidate novel therapeutic targets to facilitate the treatment of COPD using machine-based learning (ML) algorithms and penalized regression models. In this study, 59 healthy smokers, 53 healthy non-smokers and 21 COPD smokers (9 GOLD stage I and 12 GOLD stage II) were included (n = 133). 20,097 probes were generated from a small airway epithelium (SAE) microarray dataset obtained from these subjects previously. Subsequently, the association between gene expression levels and smoking and COPD, respectively, was assessed using: AdaBoost Classification Trees, Decision Tree, Gradient Boosting Machines, Naive Bayes, Neural Network, Random Forest, Support Vector Machine and adaptive LASSO, Elastic-Net, and Ridge logistic regression analyses. Using this methodology, we identified 44 candidate genes, 27 of these genes had been previously been reported as important factors in the pathogenesis of COPD or regulation of lung function. Here, we also identified 17 genes, which have not been previously identified to be associated with the pathogenesis of COPD or the regulation of lung function. The most significantly regulated of these genes included: PRKAR2B, GAD1, LINC00930 and SLITRK6. These novel genes may provide the basis for the future development of novel therapeutics in COPD and its associated morbidities.
Similar content being viewed by others


Introduction
Chronic obstructive pulmonary disease (COPD) is a progressive inflammatory disease characterized by airway obstruction and is predicted to be among the first three causes of death worldwide1,2. Clinical presentations include emphysema, small airway obstructions and chronic bronchitis. COPD has been shown to develop in 30% of smokers and smoking history, combined with reduced daily physical activity, may be the main risk factor associated with the development of COPD3. Additional risk factors in COPD, in genetically susceptible individuals, include a history of maternal smoking, second hand smoke, polluted air, maternal/paternal asthma, childhood asthma or respiratory infections and malnutrition4. Although COPD archetypically manifests itself in males, recent studies have demonstrated an increased incidence and mortality rates in females. Furthermore, female patients with COPD are more often misdiagnosed and/or underdiagnosed5,6.
From a genetic perspective, COPD is a complex disease arising from mutations in multiple alleles and the lack of integration of data in this disease has been attributed to dispersed, independent genome-wide association studies (GWAS)7. DNA microarrays now permit scientists to screen thousands of genes simultaneously in order to determine which genes are active, hyperactive or silent in normal or COPD tissue. Furthermore, network-based medicine has also been recently employed to facilitate the investigation of genomics, transcriptomics, proteomics and other “–omics” in order to better understand complex diseases, such as COPD8. However, from a biological perspective, only a only a small subset of genes identified by these methodologies will be strongly indicative of the target disease9. Therefore, in this study, we employed a novel methodology, namely machine-based learning algorithms combined with penalized regression models, in order to study genomic change in COPD in a more selective manner. Furthermore, we have also had a longstanding interest in the genetics of COPD, formally as part of a European Union consortium10,11,12,13. Here, we now extend on these initial observations.
This study was designed to apply signaling-network methodology with machine-based learning methods to better understand the genetic etiology of smoking exposure and COPD in 59 healthy smokers, 53 healthy non-smokers and 21 COPD smokers (9 of GOLD stage I and 12 of GOLD stage II) were included (Total: n = 133). Furthermore, AdaBoost Classification Trees, Decision Tree, Gradient Boosting Machines, Naive Bayes, Neural Network, Random Forest, Support Vector Machine (as machine learning algorithms) and adaptive LASSO, elastic-net, and ridge logistic regression (as statistical models) were also applied.
In summary, we identified 44 candidate genes associating with smoking exposure and the incidence/progression of COPD. We also identified 17 novel genes, which were not previously associated with COPD, the regulation of lung function or smoking exposure. The most significantly regulated of these genes included: PRKAR2B, GAD1, LINC00930, and SLITRK6. These novel genes may provide the basis for the future development of novel therapeutics in COPD and warrant further investigation and validation.
Results
Differential analysis of gene expression data
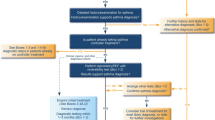
In this study, 54,675 probes were screened using the microarray dataset generated from SAE cells previously from: 59 healthy smokers, 53 healthy non-smokers and 21 COPD smokers (42.8% of GOLD stage I and 57.2% of GOLD stage II) (Table 1)14. Differential analysis was subsequently performed in order to select 20,097 probes. Subsequently, 718 probes and 544 genes (Fig. 1) were identified which were significantly changed (all p values < 0.0001) in COPD patients compared with healthy non-smokers. These genes, which include USP27X, PPP4R4, AHRR, PRKAR2B, GAD1, CYP1A1 and CYP1B1, are listed in the Supplementary File S1.

Schematic demonstrating study plan and flowchart.
Module identification
Normalized gene expression data was used for module identification in the SPD algorithm. In total, 576 modules were identified. Three modules were biologically more related to the progression and phenotype of COPD including, 119, 242 and 324. The minimal spanning trees obtained from the SPD algorithm are shown in Fig. 2. All the genes involved in COPD progression are presented in Table 2 and then included in machine-learning and statistical modeling approaches. From these three selected modules, gene expression within two of the modules (Fig. 2a,b), associated with COPD-progression, was increased in SAE cells. In contrast, gene expression within the third module (Fig. 2c), associated with COPD-progression, was decreased in SAE cells. In Fig. 2d, classification of samples was shown based on the disease stage (dark blue = healthy non-smoker, light blue = healthy smoker, light brown = COPD stage I and dark brown = COPD stage II).

Genes involved in the progression of the COPD based on the minimal- inclusive trees were obtained from SPD algorithm (dark blue = healthy non-smoker, light blue = healthy smoker, light brown = stage I of COPD smoker and dark brown = stage II of COPD smoker).
Gene selection and prediction
Based on the machine-learning and statistical penalized algorithms, and after adjustment of the effect of pack per year of smoking, elastic-net logistic regression had the highest AUC (82%), sensitivity (85%), specificity (51%) and lowest misclassification error rate (25%). In reverse, decision trees method has lowest AUC (57%), sensitivity (69%), specificity (43%) and highest misclassification error rate (39%) than other algorithms. Based on the elastic-net logistic regression, the most important selected genes included, THSD4, PPP4R4, JAKMIP3, LINC00930, DNHD1, TMCC3, CCDC37, PRDM11, GLI3, ABCC3, ADH7, SAMD5, RASSF10, USP27X, GAD1, CYP1A1, NR0B1, CYP1B1, PLAG1, PIEZO2, SCGB1A1, LOC100507560.
Consequently, 44 candidate genes identified here are associated with either the occurrence or progression of COPD, or lung function (Table 3). According to the results of each computational method, 44 were selected and the computational methods were hierarchically clustered, simultaneously (Figs 3 and 4). Of these 44 genes, 27 have been previously reported in the literature to be associated with COPD, lung function (FVC, FEV1 or the FEV1/FVC ratio) or other lung diseases. These 27 genes also include the genes of THSD4, PPP4R4, SCGB1A1, and NRG1, already detected in GWA studies to determine single nucleotide polymorphisms (SNPs) specifically for COPD (Table 4). Furthermore, in our study, SNPs within 4 additional genes have been detected in GWAS studies carried out previously in lung-related studies including: PRDM11 and AHRR FVC, smoking15,16, CYP1A1 childhood bronchitis17 and CYP1B1 lung cancer18. In this study, we have identified 17 genes which have not previously been detected in COPD studies, these include: LINC00942, REEP1, C6orf164, LINC00589, JAKMIP3, LINC00930, DNHD1, TMCC3, ADH7, PRKAR2B, GAD1, LOC338667, CYB5A, PIEZO2, SLITRK6, KCNA1 and LOC100507560 (Table 4). These genes may represent novel biomarkers in the diagnosis and prognosis of COPD. Figure 5 depicts the functional protein-association networks for the 44 selected genes, as shown by STRING.

Interactive cluster heatmap displaying importance index of the forty-four candidate genes (as columns) in each of the machine learning and statistical methods (as rows), rows and columns of the heatmap have been reordered according to a hierarchical clustering, represented by the dendrogram, colors represent importance index of the genes (red to yellow: lower to higher of importance value).

Spearman’s rank correlation, co-expression, matrix between the selected genes: heatmap for hierarchical clustering the forty-four candidate genes based on their pattern of gene expression.

STRING protein–protein interaction networks for the forty-four candidate genes.
Investigation of the differential expression of genes in healthy non-smokers (HNS; control subjects), healthy smokers, COPD patients, and COPD Stage I and II patients
In this study, we also investigated the differential expression of our 44 candidate genes in healthy non-smokers (HNS; control subjects; n = 53), healthy smokers (HS; n = 59), COPD patients (n = 21), and COPD stage I (COPD I; n = 9) and II (COPD II; n = 12) patients, respectively. We investigated the differential gene expression between HNS and HS and found significant differences in expression in 39/44 (88.6%) of all genes. In addition, 16/17 (94.1%) of the genes, not previously detected associating with COPD or lung function, were differentially expressed (Table 5; column HS v HNS). We then investigated the differential expression of these 44 genes in HS and COPD patients. Here, 24/44 (54.5%) of all genes studies were significantly regulated. Furthermore, 10/17 previously undetected genes in COPD/lung function were differentially regulated (Table 5; column COPD v HS). Finally, we investigated the regulation of these 44 genes in COPD Stage I and II patients compared with HS (Table 5; columns stage I v HS and stage II v HS). Here, we observed that 5/44 (11.4%; COPD stage I) and 16/44 (36.3%; COPD stage II) were differentially regulated. Among the previously undetected genes in COPD/lung function, 10/17 (58.8%) and 6/17 (35.3%) were significantly different in COPD stage I and II, respectively, compared with HS. A number of genes were significantly different in all four analyses (HS v HNS; HS v COPD; HS v COPD I; HS v COPD II), including: USP27X, AHRR, CYP1A1 and CYP1B1. Interestingly, of these genes, not previously identified to associate with COPD/lung function, PRKAR2B and GAD1 were significantly different in all four analyses. Therefore, this study reveals for the first time the potential role of PRKAR2B and GAD1 in COPD and smoking-related dysfunction in lung.
Investigation of the gender effect on differential gene expression in HNS, HS and COPD (Stage I and II) patients
Here we examined the effects of gender on the expression of our 44 candidate genes. We demonstrated that the expression of 40/44 (90.9%) of these genes is significantly different in HS men compared to HNS men (Table 6; HS v HNS). In addition, 15/17 (88.2%) of the novel genes previously undetected in COPD/lung function had significantly different expression levels (Table 6; HS v HNS) in men. Investigation of the expression levels of the 44 candidate genes in men with COPD versus HS revealed that 21/44 (47.7%) of genes were significantly different (Table 6; COPD v HS) and 10/17 (58.8%) of previously undetected genes in COPD/lung function were also significantly different. When HS were compared to COPD Stage I and II patients, respectively, 4/44 (Stage I; 9.0%) and 7/44 (Stage II; 15.9%) of the total candidate genes were significantly different in male HS compared to HNS. Of the 17 novel genes detected in this study, 1/17 (Stage I; 5.9%) and 3/17 (Stage II; 17.6%) were significantly different in males compared to HS (Table 6; Stage I or Stage II v HS). A number of the 44 candidate genes were significantly different in males across all four analyses, these included USP27X, AHRR, and the novel gene, JAKMIP3.
We then investigated the expression of our 44 candidate genes, including our 17 novel genes, in HNS, HS, COPD, and COPD Stage I and II. Here, we determined that 52.3% of the 44 candidate genes were significantly differentially expressed in HS compared to HNS females (Table 6; HS v HNS). In addition, 47.1% of the 17 novel genes were significantly different in HS females compared to HNS females. A comparison of female COPD patients to HS females revealed that expression of 7/44 (15.9%) of the 44 candidate genes and 2/17 (11.8%) of the 17 novel genes were significantly different in COPD patients compared to HS (Table 6; COPD v HS). Furthermore, we also observed of significant difference in COPD Stage II compared with HS in 6/44 (13.6%) of the 44 candidate genes and 2/17 (11.8%) of the novel genes detected in this study in females (Table 6; Stage II v HS). A number of the 44 candidate genes were significantly different in females across all four analyses, these included CYP1A1 and the novel genes, LINC00930, GAD1 and SLITRK6.
Investigation of the age effect on differential gene expression in HNS, HS and COPD (Stage I and II) patients
In this study, we also investigated the effect of age (i.e. subject or patient age: < or ≥50 years) on gene expression in HNS, HS, COPD patients, and stage I and II patients. We observed a significant change in the gene expression of 40/44 (90.9%) total candidate genes and 15/17 (88.2%) novel genes in subjects ≤ 50 years (Table 7; <50 years; HS v HNS). Comparison of HS to COPD patients revealed that expression of 20/44 (45.5%) of our candidate genes were significantly different in COPD patients ≤ 50 years. In addition, expression of 8/17 (47.1%) of our novel genes were significantly different in COPD patients compared to HS ≤ 50 years (Table 7; <50 years; COPD v HS). We also investigated differential gene expression in Stage I and II COPD patients ≤ 50 years and determined that 6/44 (13.6%; Stage I) and 9/44 (20.5%; Stage II) candidate genes, respectively, were significantly different in patients ≤ 50 years. In our cohort of 17 novel genes, we determined that 2/17 (11.8%; Stage I) and 3/17 (17.6%; Stage II) among our total 44 candidate genes, respectively, were significantly different in patients ≤ 50 years (Table 7; <50 years; Stage I and Stage II v HS). Furthermore, a certain number of these candidate genes were significantly different in subjects ≤ 50 years, across all four analysis groups, which included USP27X, CYP1A1 and the novel genes of JAKMIP3 and GAD1.
We then investigated the differential regulation of these 44 candidate genes in HNS, HS, COPD patients, and Stage I and II patients over 50 years (Table 7; ≥50 years). In this age group, gene expression was not significantly different. This was surprising, as the symptoms of COPD worsen with age and one would expect associated gene regulation to become more dysregulated. Specifically, a comparison of HS to HNS in subjects over 50 years revealed that expression of 16/44 (36.4%) of the candidate genes and 5/17 (29.4%) 17 novel genes were significantly different (Table 7; ≥50 years; HS v HNS). Investigation of gene expression in COPD versus HS in subjects over 50 years revealed that expression of 3/44 (6.8%) of the 44 candidate genes and 1/17 (5.9%) of the novel genes were significantly different (Table 7; ≥ 50 years; COPD v HS). Subsequently, we investigated the differential gene expression in Stage I and II COPD patients over 50 years and determined that 1/44% (2.3%; Stage I) and 0/44 (0%; Stage II), respectively, were significantly different in patients ≤50 years. In our cohort of 17 novel genes, we determined that expression of only 1/17% (5.9%; Stage I) and 0/17 (0%; Stage II) genes, respectively, were significantly different in patients ≤50 years (Table 7; ≥50 years; Stage I and Stage II v HS). Furthermore, in COPD patients over 50 years, no genes were significantly different across all four analysis groups (i.e. HS v HNS; COPD v HS; Stage I v HS and Stage II v HS).
Investigation of the effect of cigarette pack number per year on differential gene expression in HS and COPD (Stage I and II) patients
Here, we also investigated the effect of cigarette pack number per year (i.e. < or ≥50 cigarette packs/year) on the gene expression in HS, COPD patients, and Stage I and II patients. We analyzed the differential regulation of the 44 candidate genes in HS, COPD patients, and Stage I and II patients who consumed less than 50 packs/year (Table 8; <50 packs/year). In this age group, gene expression was not significantly different. Investigation of gene expression in COPD versus HS in subjects who consumed less than 50 packs/year revealed that expression of 4/44 (9.1%) candidate genes and 2/17 (11.8%) novel genes were significantly different (Table 8; <50 packs/year; COPD v HS). Subsequently, we studied the differential gene expression in Stage II COPD patients who consumed ≥50 packs/year and determined that 4/44 (9.1%) candidate genes, were significantly different in patients ≤50 years. In our cohort of 17 novel genes, we determined that the expression of only 1/17 (5.9%) of Stage II genes was significantly different in patients who consumed ≥50 packs/year compared to HS (Table 8; <50 packs/year; Stage I and Stage II v HS). Furthermore, a certain number of candidate genes were significantly different in subjects who consumed ≥50 packs/year, across in both analysis groups, which included SAMD5, PLAG1 and the novel gene, SLITRK6.
In COPD patients who consumed ≥50 packs/year, we observed a significant change in gene expression in 22/44 (50%) candidate genes and 9/17 (52.9%) novel genes compared with HS (Table 8; ≥50 packs/year; COPD v HS). We also investigated differential gene expression in Stage I and II COPD patients who consumed ≥50 packs/year and determined that 7/44 (15.9%; Stage I) and 10/44 (22.7%; Stage II) candidate genes were significantly different compared to gene expression in HSs. In our cohort of 17 novel genes, we determined that gene expression in 2/17% (11.8%; Stage I) and 4/17% (23.5%; Stage II) was significantly different in COPD patients who consumed ≥50 packs/year (Table 8; ≥50 packs/year; Stage I and Stage II v HS). In addition, a certain number of the 44 candidate genes were significantly different across all four-analysis groups, which included USP27X, CYP1A1 and the novel genes, PRKAR2B and GAD1.
Discussion
Chronic obstructive pulmonary disease (COPD) is a progressive inflammatory disease characterized by airway obstruction and is predicted to be among the first three causes of death worldwide1,2. A significant degree of clinical heterogeneity has been observed in COPD patients. In functional terms, all COPD patients experience a loss in lung function, as measured using FEV1 and FVC. However, these clinical parameters are not optimal and FEV1 has been shown to correlate weakly with clinical outcome and health status19,20. Currently, there is an unmet clinical need to identify novel biomarkers that will facilitate improved diagnosis and prognosis in COPD.
To date, COPD has been shown to develop in 30% of smokers, with smoking being one of the main risk factors associated with the development of COPD3. The aim of this project was to identify candidate novel biomarkers, which may provide future novel therapeutic targets, in order to facilitate the treatment of COPD using machine-based learning algorithms and penalized regression models. In this study, 59 healthy smokers, 53 healthy non-smokers and 21 COPD smokers (9 GOLD stage I and 12 GOLD stage II) were included (n = 133). 20,097 probes were generated from SAE microarray data obtained from these subjects previously14. Consequently, 44 candidate genes were identified to be associated with the occurrence or progression of COPD, or lung function. Of these 44 genes, 27 have been previously reported in the literature to be associated with COPD or lung function (FVC, FEV1 or the FEV1/FVC ratio). In this study, we also identified 17 genes not previously detected in COPD studies that may represent novel biomarkers in the diagnosis and prognosis of COPD. In our analyses among healthy non-smokers and healthy smokers and COPD patients (GOLD stage I and II), the most significantly regulated novel genes were: PRKAR2B, GAD1, LINC00930 and SLITRK6.
PRKAR2B is a protein kinase type II-beta regulatory subunit dependent on cAMP and encoded by the PRKAR2B gene in human21. In our overall analyses, expression of PRKAR2B was significantly downregulated in healthy smokers and in COPD patients (and in COPD stage II) compared to healthy non-smokers. Furthermore, in males, PRKAR2B expression was also significantly downregulated in healthy smokers and in COPD patients compared to healthy non-smokers. In females, these differences were less pronounced. In subjects less than 50 years, PRKAR2B expression was significantly downregulated in healthy smokers and in COPD patients compared to healthy non-smokers. In patients over 50 years, these differences were less pronounced. With regards to smoking exposure, COPD patients who smoked more than 50 packs per year had significantly lower PRKAR2B gene expression than healthy non-smokers. This decrease was not evident in COPD patients who smoked less than 50 cigarette packs per year. Thus, we hypothesise that PRKAR2B may represent a previously unknown factor both in pathogenesis of COPD and smoking exposure. PRKAR2B is an important protein kinase in cAMP signaling, and other researchers have demonstrated that cAMP is a protective factor in the lung and COPD. Furthermore, cAMP has been shown to attenuate pro-inflammatory responses whilst concomitantly increasing anti-inflammatory responses in a number of innate immune cells22. The reduced PRKAR2B gene expression observed in this study may reveal PRKAR2B as a novel target in the treatment of COPD.
In contrast, in this study we also observed a significant upregulation of the novel gene, GAD1, in healthy smokers and COPD patients (and in stage II) compared to healthy non-smokers. In male only subjects, this pattern was replicated. The increase in expression of GAD1 in healthy smokers and COPD patients compared to healthy non-smokers was marginally less significant than in male subjects, as expected. In subjects younger than 50 years, there was a more significant increase in GAD1 expression in healthy smokers and COPD patients compared to subjects over 50 years and also the non-smokers. Smoking exposure only significantly increased GAD1 levels in healthy smokers and COPD patients who smoked more than 50 packs per year. There were no significant changes in GAD1 expression in subjects who smoked less than 50 packs per year. Other studies have shown that levels of γ-aminobutyric acid (GABA) and glutamic acid decarboxylase 1 (GAD1), the enzyme that synthesizes GABA, are significantly increased in neoplastic tissues23. Furthermore, other researchers have shown that the GAD1 promoter is hypermethylated in a number of cancer cells. This effect was shown to lead to the production of high levels of GAD1, as opposed to gene silencing which one would expect. The GAD1 promoter contains a number of CpG island motifs which facilitate this hypermethylation. In this study, we hypothesise that the increased levels of GAD1 detected following smoking exposure and COPD could mean that GAD1 is an important target in the treatment of this smoking-related disease. Previous studies have demonstrated that patients with COPD are at an increased risk for both the development of primary lung cancer, as well as poor outcome after lung cancer diagnosis and treatment24. Targeting the knockdown of GAD1 in COPD may attenuate the increased risk of lung cancer in COPD patients.
LINC00930 was an additional novel gene detected in this study using machine-based learning. This is a “long intergenic non-protein coding (linc) RNA 930” (https://www.genecards.org/cgi-bin/carddisp.pl?gene=LINC00930). Interestingly, some other novel genes including LINC00942 and LINC00589 were also detected in this study. However, they were not as significantly regulated by smoking exposure or in COPD patients. In general, lincRNAs are found in between coding genes rather than antisense to them or within introns. Although the specific function of lincRNAs is not well known, they are thought to contribute to RNA stability in cells and hence gene expression. In our study, LINC009030 expression was significantly increased in healthy smokers overall, and in males and females, compared to healthy non-smokers. LINC009030 expression was significantly increased in smokers less than 50 years when only compared to non-smokers. In the over-50 age group, COPD patients had significantly less LINC009030 expression compared to healthy non-smokers. Regarding the smoking exposure, COPD patients and Stage II COPD patients who smoked less than 50 packs per year had significantly less LINC009030 expression compared to healthy non-smokers. In this study, LINC009030 was the only novel gene whose expression was significantly upregulated in smokers while significantly downregulated in COPD patients. Additional experimentation is required for elucidating the mechanism underlying this result in order to evaluate the therapeutic potential of targeting LINC009030 in smoking-related morbidities and in COPD patients.
SLITRK6 was the last novel gene, which we determined to be significantly regulated in smoking and in COPD in this study. SLITRK6 is a member of the SLITRK family of neuronal transmembrane proteins that was discovered as a bladder tumor antigen using suppressive subtractive hybridization25. Using immunohistochemistry, SLITRK6 has been shown to be extensively expressed in multiple epithelial tumors, including lung, bladder and breast cancer, as well as in glioblastoma25. In our study, we demonstrated that SLITRK6 was significantly downregulated in smokers and COPD patients (including stage II) compared to healthy non-smokers. Male smokers and COPD patients also had significantly lower SLITRK6 expression compared to non-smokers. In females, SLITRK6 expression was significantly less in smokers, but not COPD patients, compared to non-smokers. Smokers and COPD patients (including stage II) aged less than 50 years had significantly lower SLITRK6 expression compared to non-smokers. These effects were not evident in subjects over 50 years. Concerning the smoking exposure, COPD patients (including stage II) who smoked more than 50 packs per year had significantly lower SLITRK6 expression compared to non-smokers. This effect was also evident in COPD patients (including stage II) who smoked less than 50 packs per year. The highlight of this study was that the expression of the oncogenesis-promoting enzyme, GAD1, is significantly increased in response to smoking exposure and in COPD. Although SLITRK6 is considered a tumourogenesis promoting factor, it was significantly decreased in this study in responses to smoking exposure and in COPD. Here, we hypothesise that GAD1 may represent a better target in order to attenuate the incidence of cancer following COPD. However, further investigations are needed to explain the exact function of SLITRK6 in smoking-associated morbidities and in COPD.
More recently, machine-based learning algorithms have gained increasing attention in bioinformatics and biology research26,27. In contrast, regularization-based regression models (e.g. LASSO logistic regression) have already been used widely in microarray analysis28. Microarray analysis has a number of limitations including overfitting and multi-collinearity. In order to address these issues, regularization of parameters is required29. In this study, the area under the receiver operator characteristic curve (AUC), the sensitivity and specificity, and the misclassification error rate were quantitated for machine-based learning algorithm and penalty-based statistical method used. In this study based on repeated 5-CV, the elastic-net, random forest, and LASSO regularized logistic regression models were found to perform better than the naive Bayes, ridge, gradient boosting machines, adaptive boosting classification trees, extension of LASSO, artificial neural network, support vector machines, and decision tree models, respectively. Elastic-net regularization produced a sparse model with good prediction accuracy and good grouping-capability. This result is in keeping with those from previous studies, which demonstrated that elastic-net frequently performs better than ridge and LASSO for model selection consistency and prediction accuracy in microarray datasets28,30,31. Therefore, the results of this study are in agreement with those from previous ones.
In summary, we employed machine-based learning algorithms and penalized regression models in order to identify 44 candidate genes, whose expression was significantly regulated by smoking exposure and/or COPD. We also identified 17 novel genes which were not previously determined to be associated with smoking exposure or COPD. We determined that four of these novel genes, namely PRKARB2, GAD1, LINC00930 and SLITKR6, were the most significantly regulated by smoking exposure or in COPD. We also determined that elastic-net logistic regression in our dataset had a higher accuracy rate compared to the other algorithms. Therefore, in microarray data, elastic-net logistic regression may provide a useful methodology for future studies in the discovery of novel diagnostic- and prognostic-biomarkers, and novel therapeutic targets in the treatment of COPD and other smoking-related diseases.
The strengths of this study include the use of modern and accepted computational methods, the address of potential sources of bias, validation of all of the results by literature review, the use of appropriate cross-validation method (repeated 5-CV), enrichment analysis and the use of STRING networks. The main limitations of the study are the small sample sizes and that this is a case-control study only. Specifically, this study does not establish the respective associations between the 44 candidate genes and any COPD outcomes (e.g. lung function changes, exacerbations or mortality). Therefore, future studies by us will investigate and validate the candidacy of our 44 novel genes as novel therapeutic targets in COPD using larger patient cohorts. Furthermore, these studies, will investigate the association between these 44 novel genes and the change in lung function over time (FEV1 or FEV1/FVC ratio), incidence of exacerbations and mortality in COPD patients.
Methods
Study subjects and dataset
In this study, 59 healthy smokers, 53 healthy non-smokers and 21 COPD smokers (9 of stage I, GOLD I and 12 of stage II, GOLD II) were included (Total: n = 133). Subjects were predominantly male (n = 95; 71.4%) and Caucasian (n = 48; 36.1%; Table 1). Pulmonary function tests from COPD patients revealed that forced vital capacity (FVC), forced expiratory volume 1 (FEV1) and the FEV1/FVC ratio were significantly lower in these patients compared with healthy smokers and healthy non-smokers (Table 1). From these subjects, the raw data of gene expression architecture in the small airway epithelium (SAE) cells of COPD was used14. 20,097 probes from 133 subjects were generated. Genome-wide gene expression analysis (GWAS) was performed using HG-U133 Plus 2.0 array (Affymetrix, Santa Clara, CA)14. Overall microarray quality was verified by the criteria: (1) 3′/5′ ratio for GAPDH ≤3; and (2) scaling factor ≤10.0. The captured image data from the HG-U133 Plus 2.0 arrays was processed using MAS5 algorithm. The data was normalized using GeneSpring version 7.3.1 (Agilent technologies, Palo Alto, CA). See Supplemental Methods for further details. The raw data is available at the Gene Expression Omnibus (GEO) site (http://www.ncbi.nlm.nih.gov/geo/), accession number for this dataset is GSE20257.
Gene expression analysis
Raw data (.CEL format) files were qualified, normalized, statistical comparison, removing batch effects and other unwanted variation were performed by “Affy,” “Limma” and “SVA” R packages, respectively. The cutoff of false discovery rate and fold-change for differentially expressed genes was considered at level of 0.10, and more than 2, respectively.
Module identification
Sample progression discovery (SPD) as a novel unsupervised computational approach to identify patterns of biological progression underlying microarray gene expression data. SPD assumes that individual samples of a microarray dataset are related by an unknown biological process, and that each sample represents one unknown point along the progression of that process. SPD aims to organize the samples in a manner that reveals the underlying progression and to simultaneously identify subsets of genes that are responsible for that progression. This method does not depend on prior knowledge and only uses gene expression information32. In this method, divisive/consensus k-means as a clustering gene algorithm was used (200 iterations in each consensus k-means partitioning, and 0.7 threshold for module coherence). Also, least number of genes in each modules was 10. SPD analysis was done by MATLAB 7 software.
Machine learning (ML) algorithms
Various ML algorithms including AdaBoost classification trees, decision tree, Gradient Boosting machines, Naive Bayes, neural network, random forest, support vector machine were performed in order to find genes associated with occurrence and progression of COPD, and the best ML method which has best accuracy and performance to predict COPD. All ML methods were applied using “adabag”, “CART”, “gbm”, “naivebayes”, “neuralnet”, “‘randomForest”, and “e1071” R packages.
Adaptive LASSO, elastic-net, and ridge logistic regression
The ridge regression uses an L2 penalty to regularize parameters, all of the estimated coefficients are nonzero, and hence no gene selection is performed. But, LASSO regression use the L1 penalty instead, and hence provide automatic gene selection. In other hand, ridge penalty tends to shrink the coefficients of correlated variables toward each other, good for multi-collinearity, grouped selection. But, the lasso penalty is somewhat indifferent to the choice among a set of strong but correlated variables. Therefore, LASSO is good for simultaneous estimation and eliminating trivial genes but not good for grouped selection. Elastic-net is introduced as a compromise between these two techniques, and has a penalty which is a mix of L1 and L2 penalty, combine strength between ridge and lasso33. In adaptive LASSO regression where adaptive weights, inverse absolute value of LASSO coefficient was used for each variable as its weight in adaptive LASSO, are used for penalizing different coefficients in the L1 penalty. Similar to the lasso, the adaptive lasso is shown to be near-minimax optimal. Unlike to the LASSO, the adaptive LASSO is consistent for gene selection34. The mentioned penalized logistics regression methods were done by “glmnet” R package (https://cran.r-project.org/package=glmnet). In Table 9, the summary of each machine-learning and penalized statistical methods with some of advantages and limitations were mentioned.
Gene set enrichment analysis
Gene set enrichment analysis is a method to identify classes of genes that are over-represented in a large set of genes and may have an association with disease phenotypes (e.g. occurrence of COPD). The Comprehensive gene set enrichment analysis web server 2016 update called “Enrichr” was applied35.
Cross-validation, stability and accuracy
K-fold cross-validation scheme (k-cv) is a very commonly employed technique used to evaluate classifier performance. K-CV estimation of the error is the average value of the errors committed in each fold. Thus, the K-CV error estimator depends on two factors: the training set and the partition into folds. Sensitivity analysis was performed to changes in the training set and sensitivity to changes in the folds36. The bootstrap (or subsampling) is another way to bring down the high variability of cross-validation, to aims stability selection37. Repeated cross-validation is a good strategy for (a) optimizing the complexity of regression models and (b) for a realistic estimation of prediction errors when the model is applied to new cases38,39. In the present study, the algorithms split the data set by using repeated random 100 times sub-sampling in 5-fold cross-validation, permuting the sample labels every time. Cross-validated performance was summarized by observed sensitivity and specificity, and misclassification error rate. Furthermore, the area under the Receiver Operator Characteristic (ROC) curve (AUC), was used to calculate of classifiers performance40,41. Also, in order to assessing literature validation for any results, literature mining was used in the PubMed databank. Interactive cluster heatmaps was applied by “heatmaply” R package (https://cran.r-project.org/web/packages/heatmaply)42. A heatmap is a popular graphical method for visualizing high-dimensional data. A static heatmap, as an interactive heatmaps, was used to represent biological data, in which colors are used to represent the values (importance index) in a matrix where columns and rows are the machine learning and statistical methods (instances) and genes selected (attributes), respectively. Rows and columns are sorted using a hierarchical clustering technique43. The study’s follow chart is shown in Fig. 1.
References
Zhao, J. et al. Smoking status and gene susceptibility play important roles in the development of chronic obstructive pulmonary disease and lung function decline: A population-based prospective study. Medicine 96, e7283, https://doi.org/10.1097/md.0000000000007283 (2017).
Lozano, R. et al. Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010. The lancet 380, 2095–2128 (2012).
Remoortel, H. V. et al. Risk Factors and Comorbidities in the Preclinical Stages of Chronic Obstructive Pulmonary Disease. American Journal of Respiratory and Critical Care Medicine 189, 30–38, https://doi.org/10.1164/rccm.201307-1240OC (2014).
Postma, D. S., Bush, A. & van den Berge, M. Risk factors and early origins of chronic obstructive pulmonary disease. Lancet (London, England) 385, 899–909, https://doi.org/10.1016/s0140-6736(14)60446-3 (2015).
Raghavan, D., Varkey, A. & Bartter, T. Chronic obstructive pulmonary disease: the impact of gender. Current opinion in pulmonary medicine 23, 117–123, https://doi.org/10.1097/mcp.0000000000000353 (2017).
Rosenberg, S. R., Kalhan, R. & Mannino, D. M. Epidemiology of Chronic Obstructive Pulmonary Disease: Prevalence, Morbidity, Mortality, and Risk Factors. Seminars in respiratory and critical care medicine 36, 457–469, https://doi.org/10.1055/s-0035-1555607 (2015).
Rajput, C. Chronic Obstructive Pulmonary Disease Meta Genome-Wide Association Studies. New Insights into the Genetics of Chronic Obstructive Pulmonary Disease. American journal of respiratory cell and molecular biology 57, 1–2, https://doi.org/10.1165/rcmb.2017-0070ED (2017).
Silverman, E. K. & Loscalzo, J. Network medicine approaches to the genetics of complex diseases. Discovery medicine 14, 143–152 (2012).
Hardin, M. & Silverman, E. K. Chronic Obstructive Pulmonary DiseaseGenetics: A Review of the Past and a Look Into the Future. Chronic obstructive pulmonary diseases (Miami, Fla.) 1, 33–46, https://doi.org/10.15326/jcopdf.1.1.2014.0120 (2014).
Chappell, S. et al. Variation in the tumour necrosis factor gene is not associated with susceptibility to COPD. European Respiratory Journal 30, 810–812, https://doi.org/10.1183/09031936.00057107 (2007).
Haq, I. et al. Association of MMP - 12 polymorphisms with severe and very severe COPD: A case control study of MMPs - 1, 9 and 12in a European population. BMC Medical Genetics 11, 7, https://doi.org/10.1186/1471-2350-11-7 (2010).
Chappell, S. et al. Genetic variants of microsomal epoxide hydrolase and glutamate-cysteine ligase in COPD. European Respiratory Journal 32, 931–937, https://doi.org/10.1183/09031936.00065308 (2008).
Chappell, S. L. et al. The role of IREB2 and transforming growth factor beta-1 genetic variants in COPD: a replication case-control study. BMC Medical Genetics 12, 24, https://doi.org/10.1186/1471-2350-12-24 (2011).
Shaykhiev, R. et al. Cigarette smoking reprograms apical junctional complex molecular architecture in the human airway epithelium in vivo. Cellular and Molecular Life Sciences 68, 877–892, https://doi.org/10.1007/s00018-010-0500-x (2011).
Loth, D. W. et al. Genome-wide association analysis identifies six new loci associated with forced vital capacity. Nature genetics 46, 669–677, https://doi.org/10.1038/ng.3011 (2014).
Zeilinger, S. et al. Tobacco Smoking Leads to Extensive Genome-Wide Changes in DNA Methylation. PLoS ONE 8, e63812, https://doi.org/10.1371/journal.pone.0063812 (2013).
Ghosh, R. et al. Air pollutants, genes and early childhood acute bronchitis. Mutation Research/Fundamental and Molecular Mechanisms of Mutagenesis 749, 80–86, https://doi.org/10.1016/j.mrfmmm.2013.04.001 (2013).
Liu, C. et al. Genetic polymorphisms and lung cancer risk: Evidence from meta-analyses and genome-wide association studies. Lung Cancer 113, 18–29, https://doi.org/10.1016/j.lungcan.2017.08.026 (2017).
Doherty, D. E. A Review of the Role of FEV1 in the COPD Paradigm. COPD: Journal of Chronic Obstructive Pulmonary Disease 5, 310–318, https://doi.org/10.1080/15412550802363386 (2008).
Jones, P. W. Health Status and the Spiral of Decline. COPD: Journal of Chronic Obstructive Pulmonary Disease 6, 59–63, https://doi.org/10.1080/15412550802587943 (2009).
Solberg, R. et al. Mapping of the regulatory subunits RIβ and RIIβ of cAMP-Dependent protein kinase genes on human chromosome 7. Genomics 14, 63–69, https://doi.org/10.1016/S0888-7543(05)80284-8 (1992).
Oldenburger, A., Maarsingh, H. & Schmidt, M. Multiple Facets of cAMP Signalling and Physiological Impact: cAMP Compartmentalization in the Lung. Pharmaceuticals 5, 1291–1331, https://doi.org/10.3390/ph5121291 (2012).
Yan, H. et al. DNA methylation reactivates GAD1 expression in cancer by preventing CTCF-mediated polycomb repressive complex 2 recruitment. Oncogene 35, 3995, https://doi.org/10.1038/onc.2015.423 https://www.nature.com/articles/onc2015423#supplementary-information (2015).
Raviv, S., Hawkins, K. A., Malcolm, M., DeCamp, J. & Kalhan, R. Lung Cancer in Chronic Obstructive Pulmonary Disease. American Journal of Respiratory and Critical Care Medicine 183, 1138–1146, https://doi.org/10.1164/rccm.201008-1274CI (2011).
Morrison, K. et al. Development of ASG-15ME, a Novel Antibody–Drug Conjugate Targeting SLITRK6, a New Urothelial Cancer Biomarker. Molecular Cancer Therapeutics 15, 1301–1310, https://doi.org/10.1158/1535-7163.mct-15-0570 (2016).
Peng, Y. A novel ensemble machine learning for robust microarray data classification. Computers in Biology and Medicine 36, 553–573 (2006).
Cho, S.-B. & Won, H.-H. In Proceedings of the First Asia-Pacific bioinformatics conference on Bioinformatics2003-Volume 19. 189–198 (Australian ComputerSociety, Inc.).
Zou, H. & Hastie, T. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 67, 301–320 (2005).
Pan, W., Xie, B. & Shen, X. Incorporating predictor network in penalized regression with application to microarray data. Biometrics 66, 474–484 (2010).
Zou, H. & Hastie, T. Regression shrinkage and selection via the elastic net, with applications to microarrays. Journal of the Royal Statistical Society: Series B. 301-320, v67 (2003).
Ogutu, J. O., Schulz-Streeck, T. & Piepho, H.-P. In BMC proceedings. S10 (BioMed Central).
Qiu, P., Gentles, A. J. & Plevritis, S. K. Discovering biological progression underlying microarray samples. PLoS computational biology 7, e1001123 (2011).
Friedman, J., Hastie, T. & Tibshirani, R. The elements of statistical learning. Vol. 1 (Springer series in statistics New York, 2001).
Zou, H. The adaptive lasso and its oracle properties. Journal of the American statistical association 101, 1418–1429 (2006).
Kuleshov, M. V. et al. Enrichr: a comprehensive gene set enrichment analysis web server 2016 update. Nucleic acids research 44, W90–W97 (2016).
Rodriguez, J. D., Perez, A. & Lozano, J. A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE transactions on pattern analysis and machine intelligence 32, 569–575 (2010).
Kim, J.-H. Estimating classification error rate: Repeated cross-validation, repeated hold-out and bootstrap. Computational statistics & data analysis 53, 3735–3745 (2009).
Filzmoser, P., Liebmann, B. & Varmuza, K. Repeated double cross validation. Journal of Chemometrics 23, 160–171 (2009).
Braga-Neto, U. M. & Dougherty, E. R. Is cross-validation valid for small-sample microarray classification? Bioinformatics 20, 374–380 (2004).
Chang, J. C. et al. Gene expression profiling for the prediction of therapeutic response to docetaxel in patients with breast cancer. The Lancet 362, 362–369 (2003).
Dreiseitl, S. & Ohno-Machado, L. Logistic regression and artificial neural network classification models: a methodology review. Journal of biomedical informatics 35, 352–359 (2002).
Galili, T. Heatmaply: interactive heat maps (with R). Month 545 (2016).
Bacardit, J. & Llorà, X. Large‐scale data mining using genetics‐based machine learning. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 3, 37–61 (2013).
Acknowledgements
This work was supported by research grants from Tarbiat Modares University (TMU; Grant No. 1287063) and the National Institute for Medical Research Development (NIMAD; Grant No. 958812) awarded to A.K., S.M. and S.A.
Author information
Authors and Affiliations
Contributions
S.M., A.K. and S.A. performed experiments and analysis. A.K. and S.A. contributed to experimental design. S.M. and S.A. contributed to statistical analysis. M.D. and M.E.A. analysed data and wrote the paper. S.C.D. and A.K. contributed to manuscript drafting.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mostafaei, S., Kazemnejad, A., Azimzadeh Jamalkandi, S. et al. Identification of Novel Genes in Human Airway Epithelial Cells associated with Chronic Obstructive Pulmonary Disease (COPD) using Machine-Based Learning Algorithms. Sci Rep 8, 15775 (2018). https://doi.org/10.1038/s41598-018-33986-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-018-33986-8
Keywords
This article is cited by
-
Inefficient antiviral response in reconstituted small-airway epithelium from chronic obstructive pulmonary disease patients following human parainfluenza virus type 3 infection
Virology Journal (2024)
-
Development and validation of asthma risk prediction models using co-expression gene modules and machine learning methods
Scientific Reports (2023)
-
Machine learning algorithms for identifying predictive variables of mortality risk following dementia diagnosis: a longitudinal cohort study
Scientific Reports (2023)
-
The role of macrophage subtypes and exosomes in immunomodulation
Cellular & Molecular Biology Letters (2022)
-
Construction of genetic classification model for coronary atherosclerosis heart disease using three machine learning methods
BMC Cardiovascular Disorders (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
