
Abstract
Information routing is one of the main tasks in many complex networks with a communication function. Maps produced by embedding the networks in hyperbolic space can assist this task enabling the implementation of efficient navigation strategies. However, only static maps have been considered so far, while navigation in more realistic situations, where the network structure may vary in time, remains largely unexplored. Here, we analyze the navigability of real networks by using greedy routing in hyperbolic space, where the nodes are subject to a stochastic activation-inactivation dynamics. We find that such dynamics enhances navigability with respect to the static case. Interestingly, there exists an optimal intermediate activation value, which ensures the best trade-off between the increase in the number of successful paths and a limited growth of their length. Contrary to expectations, the enhanced navigability is robust even when the most connected nodes inactivate with very high probability. Finally, our results indicate that some real networks are ultranavigable and remain highly navigable even if the network structure is extremely unsteady. These findings have important implications for the design and evaluation of efficient routing protocols that account for the temporal nature of real complex networks.
Similar content being viewed by others
Introduction
Transfer of information, mass, or energy is a key function in many natural and artificial complex systems, ranging from gene-regulatory networks1 and the brain2 to online and offline social networks3, the Internet4, and transportation networks5. Milgram’s experiment6 showed that some of these systems can be efficiently navigated, i.e., their elements are able to perform an effective information routing even though they do not possess global knowledge of the system. This surprising property was first explained by Kleinberg using a network model7,8, in which each node resides in the Euclidean plane and forwards information to the neighbor which is closer to destination. More recently, it has been suggested that the geometry of complex networks is not Euclidean but hyperbolic, as a result of the interplay between the popularity and similarity attributes of the nodes9,10,11,12. Within this framework, the observed topological properties of complex networks are naturally explained on the basis of a hidden metric space defining distances between nodes, and a connection probability dependent on such distances. Moreover, distances in the underlying hyperbolic geometry can guide greedy routing very efficiently in scale-free networks, meaning that the success probability of the process is extremely high, while the routing paths deviate only slightly from the topological shortest paths, following closely the geodesics in the hyperbolic plane13.
These advances in the understanding of the navigability of complex networks are framed within the traditional approach taking the structure of networks as static. However, this assumption has been recently challenged by the empirical observation of a temporal dimension in many natural and social systems14,15,16,17, demonstrating that nodes and edges switch on and off with several time scales. The empirical analysis of such temporal networks18 has unveiled new statistical properties, such as a heavy-tailed distribution of inter-event times between consecutive links, known as burstiness19, or the heterogeneous distribution of activity in social interactions20. Temporal effects have been shown to impact both the behavior of dynamical processes on networks21,22,23,24,25 and the connectivity of their corresponding static representations26,27. Time-respecting paths18, for instance, play a crucial role in slowing down or speeding up the spreading of information or diseases28, and certainly affect also the message routing throughout the network.
Although navigation is expected to be substantially different in temporal networks than in static ones, few empirical or theoretical works have been devoted to study the impact of the temporal dimension on the navigability of complex systems4,29,30. Some of these studies are concerned with the small world property31, while others aim at quantifying network vulnerability to temporary failures32, or explore temporal networks using greedy walks that proceed from node to node by always following the first available contact33. However, the general mechanisms that guarantee an optimal routing in situations where the network’s structure changes with time, or where noise affects the communication paths, are not fully understood yet. Uncovering such mechanisms is thus a fundamental task, with a broad range of potential applications, for instance, in communication engineering34 and system biology35.
Here, we tackle this issue by proposing a hybrid model to study the navigability of temporal networks and show that, surprisingly, temporal networks can be navigated more efficiently than their static counterparts. Furthermore, we show that some real networks are ultranavigable, meaning that they remain highly navigable even when the network topology is strongly dynamic. Our model considers static reconstructions of real networks and a simple node activation-inactivation dynamics. This allows us to control for the maximum duration of the routing process, as well as to discard peculiar features of specific real evolving systems, such as circadian rhythm36. The activation dynamics may represent temporal failures of nodes due to random unknown events, or noise. Our approach suggests a new greedy routing protocol in static networks, that combines standard greedy routing and a simulated activation dynamics, which can boost the navigability of some real networks, at the expense of elongated paths.
Next, we set our analysis upon five different empirical networks: ArXiv collaborations (ArXiv), US Commodities networks (Commodities), Metabolic networks (Metabolic), the Internet at the autonomous system level (Internet) and the World Trade Web (WTW). Detailed descriptions of the data sets can be found in Methods.
Greedy routing on temporal networks
Information packets, or other assets, are transferred in a network from a source node to a destination one by following greedy routing in hyperbolic space11. We consider a two-dimensional hyperbolic plane of constant negative curvature where each node i has polar coordinates (r i , θ i ), see Methods. The implementation of the routing algorithm requires that there is only one packet per source-destination pair, that each node knows its coordinates, the coordinates of its neighbors in the network, and the coordinates of the destination node. Then, the node holding the packet will transfer it to its neighbor with the smallest hyperbolic distance to the destination node.
We take the hyperbolic embedding of the largest connected component37 of each real complex network, that we refer as the static map \({ {\mathcal M} }({G}_{0},S)\), where G 0 stands for the static graph and S is the underlying metric space where the nodes have permanent coordinates. Next, we generate several synthetic temporal networks by applying a Poissonian activation-inactivation dynamics on its nodes. We consider that nodes can be in an active state, being able to receive and forward information, or in an inactive state, in which case they cannot receive neither forward information packets. At each time step t, each node i is active with probability a i . Thus, at each time step t, a graph G t is defined, in which only active nodes and the links between them are present. The sequence of graphs \({\mathscr{G}}={\{{G}_{t}\}}_{t=1,2,\ldots T}\) constitutes a synthetic temporal network of length (duration) T. The activation probabilities control the density of the temporal networks, affecting the probability of a message being sent. For instance, in the case of a constant activation probability set equal for all nodes, a i = a, each graph G t has an expected average degree equal to \({\overline{k}}_{t}=a\,\overline{k}\), where \(\overline{k}\) is the average degree of the original static network.
Therefore, the greedy routing acts on a temporal map \({\mathscr{M}}({\mathscr{G}},\,S)\) depending on the temporal network \({\mathscr{G}}\) and the underlying hyperbolic space S. The greedy forwarding algorithm is implemented sequentially on the temporal map \({\mathscr{M}}({\mathscr{G}},S)\), so there is one attempt to forward the information packet for each time step t. At time t, the node holding the information packet tries to forward it to its neighbor with the lowest distance to the final destination. If the neighbor is active at time t, then it receives the packet. Otherwise, the packet remains at the holding node. The model with a = 1 corresponds to greedy routing on the original static network, with all nodes active at all times, for a number of steps equal to T. Therefore, the network’s duration T can be interpreted as the maximum lifetime of information packets. In this scenario, a greedy path is successful when a packet reaches its destination in a time t ≤ T, and unsuccessful otherwise. In the limit of T → ∞, all packets are expected to be able to reach their destination because the number of different paths that can be realized by greedy routing on the temporal networks grows with T.
We run numerical simulations for different network’s duration T, taking a number of random source–destination pairs which is the minimum between 105 and N(N − 1)/2, where N is the number of nodes of the network. In numerical experiments varying the activation probability, the random subset of source–destination node pairs is kept the same, while it is changed when varying T.
Results
We first consider a constant activation probability set equal for all nodes, a i = a. In this case, the model is characterized by two parameters, the activation probability a, which controls the activation dynamics, and the network’s duration T, which represents the maximum lifetime of information packets. We evaluate the performance of greedy routing on the temporal map by measuring two main quantities: the success ratio p s , defined as the fraction of packets that successfully reach their destination within a time T over the total number of source-destination pairs considered; and the average topological stretch \(\bar{s}\) of successful greedy paths, where the stretch is defined as the ratio between the hop-length of a greedy path and the shortest path between the corresponding source and destination nodes. The stretch tells us how much the successful greedy paths are longer with respect to the shortest ones.
In the Supplementary Material, we also give results for the average geometric stretch \({\bar{s}}_{g}\), which is defined analogously to \(\bar{s}\) but considering the hyperbolic lengths of greedy and shortest paths; and the average coverage \(\bar{\kappa }\), which informs of the average number of different visited nodes against the average number of nodes that compound a successful path.
Effects of network dynamics on navigability
The success ratio p s is a key parameter in determining the navigability of complex networks. A large success ratio, close to \({p}_{s}\sim 1\), means that almost all nodes can be reached by a message sent by any other node. On the contrary, if p s is small, information can not be successfully transmitted from most nodes. Figure 1, top row, shows the fraction of successful paths p s as a function of the network duration T, for different values of the activation probability a. The success ratio varies considerably across different static networks (a = 1), ranging from very low success ratio for the ArXiv, to \({p}_{s}\sim 1\) for the WTW and the Internet, which indicates a better congruence of these systems with their underlying geometry. Remarkably, for sufficiently large T, the success ratio in all temporal networks (a < 1) under consideration is larger than the one achieved on their static counterparts (dashed line, top row Fig. 1 and Table 1 in Methods). This effect is particularly evident for the cases where p s in the static map is rather low, such as for the ArXiv network, where the success ratio increases from p s = 0.24 for a = 1 to p s = 0.90 for \(a\sim 0.2\). Nonetheless, when the static success ratio is high (e.g. Internet), p s on the temporal maps increases too.

Success ratio p s (top row) and average stretch \(\bar{s}\) (bottom row) as a function of T, for different values of the activation probability a, in five real networks. The success ratio and the average stretch in the static map, a = 1, appear plotted with dashed lines.
As expected, p s is a growing function of the network duration T: the larger the maximum lifetime of the packets, the higher p s . In the limit of T → ∞, p s is expected to reach its maximum since, for any pair of nodes, all different paths between them will be available at some time, ensuring that a successful one will certainly arise. This implies that the success ratio always increases with T, although the growing rate can be extremely slow for very large T. Oppositely, in the routing on static networks, p s does not vary with T because no new paths are added by increasing the lifetime of information packets.
Our results show that, surprisingly, it is more efficient to have some (or even a great number of) nodes inactive than having all nodes active and contributing to the routing process. The reason for this behavior is rooted in the fact that, with a = 1, some packets might get stuck into topological traps. From the greedy routing definition, indeed, it is clear that if a packet comes back to a node twice, it will come back again, and the loop would continue forever with the packet never reaching its destination.
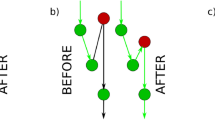
To understand this mechanism, consider a node i sending a packet to his neighbor j, because j is the closest (among all i’s neighbors) to destination node k. If during the next time step, node i turns out to be the closest node to destination k among j’s neighbors, then the packet will return to i. As long as no topological change takes place in the network, this process will repeat endlessly. Any cycle involving a packet coming back to a node twice constitutes a topological trap, See Fig. 2. In contrast, if a < 1, the topology of the network changes at each time step, hence the packet is able to escape any topological traps it may encounter along the route and eventually reach its destination. Nevertheless, the new successful path followed by the packet will deviate from the geodesic connecting the two nodes in the hyperbolic plane, thus the path length will necessarily be longer than the shortest.

Representation of a topological trap, in Euclidean space. Greedy routing demands sending the information packet always to the neighbor closest to destination. Consequently, in (a) the packet never stops jumping between nodes i and j and is captured by the topological trap, while in (b) the inactivation of i enables the packet to follow an alternative route through l and successfully reach the destination node k.
The average topological stretch \(\bar{s}\), defined as the ratio between the hop-length of greedy paths and the corresponding shortest paths in the network, is also a measure of navigation efficiency. From its definition, it holds that \(\bar{s}\ge 1\). A small stretch, \(\bar{s}\gtrsim 1\), indicates that most packets follow a route very close to the shortest one, while if \(\bar{s}\gg 1\), paths are much longer. Figure 1, bottom row, shows the average stretch \(\bar{s}\) as a function of the network’s duration T, for different values of the activation probability a. As for the success ratio, \(\bar{s}\) is also an increasing function of T. Indeed, the larger the duration T, the lengthier the paths that become successful, and these very long paths increase the average stretch.
It is important to note that the shortest paths between two nodes in \({\mathscr{M}}({\mathscr{G}},S)\) may be much longer than the shortest path in the corresponding static maps, because of time-respecting paths. This is particularly true for very sparse temporal networks, i.e. with low activation probability. Therefore, \(\bar{s}\) is always greater in temporal maps than in the corresponding static ones, as shown in Fig. 1, demonstrating that the activation dynamics is responsible for creating lengthier successful paths.
This effect is clearly visible in those data sets where p s in the static networks is low, such as the ArXiv or Commodities. In these networks, the large increase in the success ratio due to the activation dynamics comes with a large growth in the average stretch. The probability of finding much more successful tracks is increased at the cost of choosing longer paths. On the contrary, if p s in the static maps is high, such as for the Internet or the WTW, \(\bar{s}\) shows a small increase in the temporal maps. These different profiles correspond to the different geometricity of the considered networks. In fact, the less congruent topology and geometry are, the larger the number of topological traps present in \({\mathscr{M}}({\mathscr{G}},S)\) and the larger the potential increase in success. Temporal maps with limited congruency, such as ArXiv or Commodities, show the larger gains in success overcoming traps at the expenses of a notable increase in \(\bar{s}\), and longer durations T. On the contrary, networks with a conspicuous latent geometry, like the Internet and the WTW, are not characterized by a large number of topological traps, hence \(\bar{s}\) does not rise as much.
Interestingly, different effects are obtained on the success ratio and the stretch depending on the activation probability. The lowest values of \(\bar{s}\) are found for intermediate values of a, while p s generally increases as the activation probability decreases, down to a value for which the network becomes too inactive, and then p s becomes lower again. In most networks, p s remains almost unchanged if the activation probability is set equal to a = 0.3 or to a = 0.1 in the limit of large T, while \(\bar{s}\) significantly increases if the activation decreases from a = 0.3 to a = 0.1, specially for the Internet and the WTW. Conversely, choosing a = 0.6, p s grows from 0.96 in the static case to 0.99 for the Internet and from 0.99 to 0.997 in the WTW, but the stretch increases very little from \(\bar{s}=1.11\) to \(\bar{s}\approx 1.76\) for the Internet, and from \(\bar{s}=1.04\) to \(\bar{s}\approx 1.29\) for the WTW. This indicates it may exist an optimal activation probability that maximizes the increase in the success ratio and minimizes the increase in the stretch.
Optimal activation probability
Top row of Fig. 3 shows \(\bar{s}\) as a function of the activation probability a, for several values of the network’s duration T. Interestingly, the average stretch is not a strictly decreasing function of a, but it reaches a minimum for some intermediate value. On the one hand, when the activation probability is very small, the stretch is typically large because of the lack of available active neighbors. The packet will usually remain in the holding node or it will be transferred erratically, resulting in an increase of \(\bar{s}\). On the other hand, if \(a\lesssim 1\), the topology of \({\mathscr{M}}({\mathscr{G}},\,S)\) is similar to the static one, so the packet tends to fall into the same topological traps spending a long time moving in cycles (thus increasing the stretch) before it succeeds to escape the loop. Remarkably, the minimum of \(\bar{s}\) is reached for some optimal value of the activation probability, a = a O .

Average stretch, \(\bar{s}\) (top row), and success ratio divided by the average stretch, \({p}_{s}/\bar{s}\) (bottom row) as a function of a. Each curve corresponds to a different value of the duration T. Notice the rightmost point is not 1 (the static reference) but 0.96. The optimal activation a O of each network is observed as a maximum in the plots of the bottom row. The approximate values of a O for each network are: \({a}_{O}^{{\rm{Arx}}}\approx 0.25\), \({a}_{O}^{{\rm{Com}}}\approx 0.25\), \({a}_{O}^{{\rm{Met}}}\approx 0.33\), \({a}_{O}^{{\rm{Int}}}\approx 0.60\) and \({a}_{O}^{{\rm{WTW}}}\approx 0.67\).
This feature is addressed in more detail in the bottom row of Fig. 1, which shows the ratio between the success ratio and the average stretch (\({p}_{s}/\bar{s}\)) as a function of the activation probability a. Since \({p}_{s}\leqslant 1\) and \(\bar{s}\geqslant 1\) by definition, perfect navigability is reached when \({p}_{s}=\bar{s}=1\), and thus \({p}_{s}/\bar{s}=1\). The ratio \({p}_{s}/\bar{s}\) represents a measure of the trade-off between the increase in both the success ratio and the stretch. The larger the ratio, the more efficient the navigation.
For each network under consideration, it exists an optimal value a O of the activation probability that maximizes the trade-off between success ratio and stretch. For the ArXiv and the Commodities, the curves of the ratio \({p}_{s}/\bar{s}\) as a function of a depend on the duration T, with larger \({p}_{s}/\bar{s}\) for smaller T, while for the Internet and the WTW, these curves are independent of T and collapse. Figure 3 shows that the WTW combines the largest success ratio with the smallest stretch, followed by the Internet, Metabolic, Commodities and the ArXiv networks.
However, it is important to remark that the \({p}_{s}/\bar{s}\) ratio is always higher for the static maps than for the temporal ones. For instance, the static value for the Internet is \({p}_{s}/\bar{s}=0.87\) (see Table 1 in Methods), while in the temporal network it does not exceed 0.70. This is due to the fact that in temporal maps a large gain in the success, which is bounded with a top value of 1, necessarily comes with an increase in the stretch, which can be quite limited, as for the Internet or the WTW, but it is unbounded.
Heterogeneous activation dynamics
In this section, we analyse how navigation is affected by an activation probability which varies across nodes. We do it in two different fashions: (i) constant activation probability a < 1 only for nodes whose degree belongs to a certain interval, and (ii) activation probability linearly depending on nodes’ degrees.
Activation of nodes within degree intervals
Here, the random activation dynamics is targeted to subsets of equal number of nodes with degrees in a certain range of values. We measure the success ratio when only one of these subsets of nodes is randomly activated-inactivated with constant a and the rest of the network remains active. To implement this prescription, we order all nodes in a network from highest to lowest degree and divide this sorted list in segments of same number of nodes. The node bins are then labeled using the average degree \(\bar{k}\) of the nodes belonging to that bin. The size of the bins has been set to ξ = 5% of the total number of nodes N.
This method aims at identifying which degree intervals have a major contribution to the destruction of topological traps, and hence specially boost the success. We find that all temporal maps \({\mathscr{M}}({\mathscr{G}},S)\) experience a sudden increase in p s when \(\bar{k}\) is at its maximum, see Fig. S2 in SM. In scale-free networks, node degrees are distributed as a power-law \(p(k)\sim {k}^{-\gamma }\) (the γ values for the considered networks are reported in Table 1, Methods). This means that the interval \({\bar{k}}_{{\rm{\max }}}\) contains not only the biggest hub but also several densely connected nodes. Therefore, our results imply that switching on and off nodes with low degree has a limited effect on the efficiency of navigation. In fact, the higher the degree of a node the more radical the changes it can induce in the direction of a greedy path.
When we construct the bin with temporal behaviour by sampling the nodes uniformly at random from any part of the degree spectrum, so that the bin is approximately characterized by the \(\bar{k}\) of the entire network, we find a low p s close to the static and similar to that obtained for bins of low degree nodes. Therefore, not all nodes are equally able of beating topological traps, and the increase in success mostly relies on activation dynamics affecting densely connected nodes. Also, notice that activating with a < 1 some randomly selected nodes is not equivalent to activating the whole network with the corresponding average probability \(\bar{a}=1-\xi \mathrm{(1}-a)\). This is due to the fact that, while navigating the network, some nodes are visited more often than others. If all visited nodes can activate with some \(\bar{a} < 1\), the actual noise affecting the network becomes effectively greater than in our implementation.
When information packets are able to escape cycles, and the success rises due to the emergence of new (lengthier) successful paths, the average stretch increases too. We corroborate this statement in the bottom row of Fig. S2 in SM, which shows that the maximum stretch precisely occurs at \({\bar{k}}_{{\rm{\max }}}\) in all networks. As expected, the highest \(\bar{s}\) is always found for the minimum activation a = 0.1, which corresponds to the situation where packets find most nodes along their routes to be inactive so they are constantly redirected, thus producing long greedy paths. Interestingly, at \({\bar{k}}_{{\rm{\max }}}\) the \(\bar{s}\) for a = 0.9 considerably varies across networks, with the ArXiv exhibiting the highest value, then Commodities, Metabolic, Internet and finally the WTW. This supports the idea that more congruent networks posess less topological traps. In general it is also satisfied that a values around a O display lower \(\bar{s}\) at \({\bar{k}}_{{\rm{\max }}}\).
Linear activation depending on degree
Here, we study the navigability of temporal maps in which the activation probability of a node i, a i , depends linearly on its degrees k i , such as
For b > 0, the activation probability is proportional to the node’s degree so the larger the degree the more active is the node; if b < 0, the opposite is true, and if b = 0 we recover the case of constant activation probability. The average activation probability \(\bar{a}\) of the whole network, \(\bar{a}={N}^{-1}{\sum }_{i=1}^{N}\,{a}_{i}(k)\), varies depending on the choices of the coefficients b and c. We set the average activation probability \(\bar{a}\) as an independent parameter, and choose c so that \(c=\bar{a}-b\overline{k}\). The constraints for the coefficient b arise from the network’s minimum and maximum degree, k min and k max , respectively, as
For each network under consideration, we choose two values of the coefficient b (one positive and one negative) that ensure the highest heterogeneity in the activation probability, without completely inactivating any of the nodes, i.e. a(k min ) > 0 and a(k max ) > 0. Details regarding the choice of the coefficient can be found in the SM.
Figure 4 shows the effects of a heterogeneous activation probability of nodes, positevely (b > 0) and negatively (b < 0) correlated to their degree k, compared with constant activation probability (b = 0), for \(\bar{a}=0.5\). We observe that when the activation probability is proportional to k, all \({\mathscr{M}}({\mathscr{G}},S)\) tend to exhibit lower success ratios than in the case with the same \(\bar{a}\) but constant activation probability. This effect can be understood by considering that highly connected nodes are visited more often than the rest during the routing process. Consequently, the system exhibits an effective \(\bar{a}\) higher than 0.5, which induces lower p s values (closer to the static reference) as shown in previous results. The same reasoning explains the observed behaviour of the stretch \(\bar{s}\) in bottom row of Fig. 4. For all networks and when b > 0, the tendency of \(\bar{s}\) is comparable to that found for \(\bar{a} > 0.5\) in the constant activation case, see bottom row Fig. 1. This feature is specially noticeable for the Internet, where \(\bar{s}\) growth is similar to the obtained for \(\bar{a}=0.9\).

Success ratio p s (top row) and average stretch \(\bar{s}\) (bottom row) as a function of T for \(\bar{a}=0.5\), see Fig. S4 in SM for other values of \(\bar{a}\). Solid lines designate constant activation of nodes, while symbols indicate that nodes activate linearly with b > 0, or b < 0. The minimum and maximum activation probabilities allowed are 10−3 and 1–10−3 respectively. As a reference, the values for the static networks, a = 1, are given in Table 1.
On the opposite situation, for b < 0, when the activation probability gets lower as nodes become more connected, the reversed phenomenon occurs. Figure 4 (bottom row) shows that for all \({\mathscr{M}}({\mathscr{G}},S)\), the \(\bar{s}\) resembles that found for low constant \(\bar{a}\)’s. Moreover, a small increase in p s with respect to b = 0 is visible for the ArXiv, the Commodities, and the Metabolic networks in top row of Fig. 4. The cause is an effective overall activation \(\bar{a} < 0.5\). For the Internet, p s still grows higher for b < 0 than for b = 0, though it is barely appreciable, and it requires large T. For the WTW, p s reaches 1 for any b so we can not observe an incremented p s . However, we note that p s growth for the WTW is retarded when b < 0, just as happens for the Internet. In these two last networks, the influence of the largest hub on the routing performance is remarkable due to their strong hierarchical nature. For this reason, the time T needed for achieving \({p}_{s}\sim 1\) is noticeably enlarged in the event that the main hub is poorly activated.
Discussion
Navigability is a primary function in many complex networks that, as we have shown, can be strongly affected by temporal alterations in the activity of nodes. The interplay between the activation dynamics generating the temporal networks and the greedy routing process, indeed, yields a rich phenomenology. The activation process can be understood as the result of random events, like service failures, or, alternatively, it could be thought as part of a local information transfer protocol applied by the node holding the packet in a static network, so to boost the success of the routing operation at a limited cost.
Our results show that, surprisingly, temporal maps can be navigated more efficiently than the corresponding static ones, even though the number of simultaneously available paths to transfer the packets is greatly reduced. Interestingly, the number of successful paths, in which the packet reaches its destination, is increased due to the activation dynamics. This increase in the success ratio p s comes at the cost of a growth in the stretch \(\bar{s}\), meaning that longer paths are required to successfully deliver the packet. However, the ratio between the success and the stretch, \({p}_{s}/\bar{s}\), shows a non-trivial behavior as a function of the activation probability, unveiling the existence of an optimal value which maximizes the increase in the success and at the same time minimizes the increase in the stretch.
More realistic forms of the activation probability, i.e., when the dynamics only affects a subset of nodes or when the activation is correlated with the degree, show similar results. This analysis uncovered the role of highly connected nodes in the routing process, which are mainly responsible for the larger success ratio achieved in temporal maps. Contrary to expectations, our findings suggest that it is possible to improve the routing performance by switching on and off the hubs of the network more often than the rest of the nodes. Finally, the navigability of some real networks, like the Internet and the WTW, remains extremely high in the temporal maps. In fact, time-varying effects increase even more the high success rate associated to the static maps, at the cost of a very small increase in the stretch, slowly growing with T, a feature that we name ultranavigability. Even more, temporal changes in the structure of these networks increase the success even if the activation probability is very low. At the same time, the high routing success observed in these networks could be due in part to temporal behavior in the system, although this possibility has not been acknowledged before and all the merit for their navigability properties has been accredited to their static architecture.
Our work sets a first attempt to measure the effects of temporal dynamics on the navigability of real networks. It has been increasingly recognized, indeed, that networks are dynamic entities that evolve in time, with connections being established and terminated for different reasons. This study paves the way towards a better understanding of the role of the network’s temporal dimension in navigation processes, and provides hints for developing better routing strategies exploiting such dynamics. Further research is in order to extend our results. One may consider more sophisticated generative models of temporal networks, that may, for instance, incorporate a bursty dynamics of links or nodes.
Methods
Empirical data
Here we give a brief description of the five networks considered in our study and source references for their data. In Table 1, we report the values of different metrics for the five networks. Notice that we used the giant connected component in all cases.
ArXiv
The ArXiv network is a graph representing co-authorship of papers38, elaborated from data of the free scientific repository ArXiv. The nodes are authors which are connected if they have co-authored a paper belonging to category “Disordered Systems and Neural Networks” (cond-mat.disnn). The data considers only papers from up to May 2014, with the word “networks” in the title or abstract. The hyperbolic embedding of this network comes from ref.39.
US Commodities
The commodities network40 is a representation of the flows of services and goods (in USD) exchanged between industrial sectors during year 2007 in the United States. The hyperbolic embedding of this network comes from ref.41.
Metabolic
The metabolic network used in this study corresponds to the one-mode projection of metabolites of the bipartite metabolic network of the bacterium E. coli. In this representation, two metabolites are connected if they participate in the same biochemical reaction. We use the data originally extracted from the BiGG database42 and reconstructed in43 as a spatially embedded network.
Internet
We use the connectivity data for the Internet at the autonomous systems level collected by the Archipelago project44 corresponding to June 2009 and reconstructed as a network embedded in hyperbolic space in ref.11.
WTW
The world trade web consists of significant trade exchanges between countries. We use the network corresponding to the most recent data available, the year 2013, and its embedding as given in ref.45.
Hyperbolic maps
In the hyperbolic hidden metric space, every node i has coordinates (r i , θ i ). Embedding a network in a metric space means constructing a map that correlates topology and geometry. The idea is that a link between two nodes in the topology exists with a certain probability p(d) that depends on their distance d, measured in the hidden metric space, such that nodes with higher probabilities of being connected are closely positioned in the geometric space9. Therefore, p(d) needs to be a decreasing function of distance between nodes. In the hyperbolic plane, the distance between nodes d ij is calculated using the hyperbolic law of cosines:
It has repeatedly been shown that real networks can be embedded into a hyperbolic plane11,43, in a way that all relevant topological properties of the networks, such as the small world property, the degree distribution, degree-degree correlations, the clustering coefficient, and degree-thresholding topological self-similarity9 are reproduced by the model.
References
Tkačik, G., Callan, C. G. & Bialek, W. Information flow and optimization in transcriptional regulation. Proceedings of the National Academy of Sciences 105, 12265–12270 (2008).
Papo, D., Buldú, J. M., Boccaletti, S. & Bullmore, E. T. Complex network theory and the brain. Philosophical Transactions of the Royal Society B 369, 1653 (2014).
Zhang, J. Greedy forwarding for mobile social networks embedded in hyperbolic spaces. In ACM SIGCOMM2013 Conference, 555–556 (SIGCOMM’13, Hong Kong, China, 2013).
Papadopoulos, F., Krioukov, D., Boguñá, M. & Vahdat, A. Greedy Forwarding in Dynamic Scale-Free Networks Embedded in Hyperbolic Metric Spaces. In 2010 Proceedings IEEE INFOCOM, 1–9 (2010).
Bast, H. et al. Fast routing in very large public transportation networks using transfer patterns. In Proceedings of the 18th Annual European Conference on Algorithms: Part I, ESA’10, 290–301 (Springer-Verlag, Berlin, Heidelberg, 2010).
Travers, J. & Milgram, S. An experimental study of the small world problem. Sociometry 32, 425–443 (1969).
Kleinberg, J. M. Navigation in a small world. Nature 406, 845 (2000).
Easley, D. & Kleinberg, J. Networks, Crowds, and Markets: Reasoning About a Highly Connected World (Cambridge University Press, 2010).
Serrano, M. Á., Krioukov, D. & Boguñá, M. Self-similarity of complex networks and hidden metric spaces. Physical Review Letters 100, 078701 (2008).
Krioukov, D., Papadopoulos, F., Vahdat, A. & Boguñá, M. Curvature and temperature of complex networks. Phys. Rev. E 80, 035101 (2009).
Boguñá, M., Papadopoulos, F. & Krioukov, D. Sustaining the internet with hyperbolic mapping. Nature Communications 1 (2010).
Papadopoulos, F., Kitsak, M., Serrano, M. Á., Boguná, M. & Krioukov, D. Popularity versus similarity in growing networks. Nature 489, 537–540 (2012).
Boguñá, M., Krioukov, D. & Claffy, K. Navigability of complex networks. Nature Physics 5, 74–80 (2009).
Corral, A. Long-term clustering, scaling, and universality in the temporal occurrence of earthquakes. Phys. Rev. Lett. 92, 108501 (2004).
Thompson, W. H., Brantefors, P. & Fransson, P. From static to temporal network theory - applications to functional brain connectivity. bioRxiv (2016).
Goh, K.-I. & Barabási, A.-L. Burstiness and memory in complex systems. Europhysics Letters 81, 48002 (2008).
Jo, H.-H., Pan, R. K. & Kaski, K. Emergence of Bursts and Communities in Evolving Weighted Networks. PLOS ONE 6, e22687 (2011).
Holme, P. & Saramäki, J. Temporal networks (Springer, Berlin, 2013).
Barabási, A.-L. The origin of bursts and heavy tails in human dynamics. Nature 435, 207–211 (2005).
Perra, N., Gonçalves, B., Pastor-Satorras, R. & Vespignani, A. Activity driven modeling of time varying networks. Scientific Reports 2, 469 (2012).
Karsai, M. et al. Small but slow world: How network topology and burstiness slow down spreading. Phys. Rev. E 83, 25102 (2011).
Kivela, M. et al. Multiscale Analysis of Spreading in a Large Communication Network. J. Stat. Mech. (2012).
Starnini, M., Baronchelli, A., Barrat, A. & Pastor-Satorras, R. Random walks on temporal networks. Phys. Rev. E 85, 56115 (2012).
Lambiotte, R., Tabourier, L. & Delvenne, J.-C. Burstiness and spreading on temporal networks. Eur. Phys. J. B 86, 320 (2013).
García-Pérez, G., Boguñá, M. & Serrano, M. Á. Regulation of burstiness by network-driven activation. Scientific Reports 5, 9714 (2015).
Parshani, R., Dickison, M., Cohen, R., Stanley, H. E. & Havlin, S. Dynamic networks and directed percolation. Europhysics Letters 90, 38004 (2010).
Moinet, A., Starnini, M. & Pastor-Satorras, R. Aging and percolation dynamics in a Non-Poissonian temporal network model. Phys. Rev. E 94, 22316 (2016).
Scholtes, I. et al. Causality-driven slow-down and speed-up of diffusion in non-Markovian temporal networks. Nature Communications 5 (2014).
George, B., Kim, S. & Shekhar, S. Spatio-temporal Network Databases and Routing Algorithms: A Summary of Results. In Proceedings of the 10th International Conference on Advances in Spatial and Temporal Databases, SSTD’07, 460–477 (Springer-Verlag, Berlin, Heidelberg, 2007).
Kirst, C., Timme, M. & Battaglia, D. Dynamic information routing in complex networks. Nature Communications 7, 11061 (2016).
Tang, J., Scellato, M., Musolesi, M., Mascolo, C. & Latora, V. Small-world behaviour in time-varying graphs. Phys. Rev. E 81 (2010).
Trajanovski, S., Scellato, S. & Leontiadis, I. Error and attack vulnerability of temporal networks. Phys. Rev. E 85 (2012).
Saramäki, J. & Holme, P. Exploring temporal networks with greedy walks. Eur. Phys. J. B 88, 334 (2015).
Naumov, V. & Gross, T. Scalability of Routing Methods in Ad Hoc Networks. Perform. Eval. 62, 193–209 (2005).
Tononi, G., Edelman, G. M. & Sporns, O. Complexity and coherency: integrating information in the brain. Trends in Cognitive Sciences 2, 474–484 (2017).
Jo, H.-H., Karsai, M., Kertész, J. & Kaski, K. Circadian pattern and burstiness in mobile phone communication. New Journal of Physics 14 (2012).
Newman, M. E. J. Networks: An introduction to complex networks (Oxford University Press, Oxford, 2010).
Domenico, M., Lancichinetti, A., Arenas, A. & Rosvall, M. Identifying modular flows on multilayer networks reveals highly overlapping organization in interconnected systems. Phys. Rev. X 5 (2015).
Kleineberg, K., Boguñá, M., Serrano, M. Á. & Papadopoulos, F. Hidden geometric correlations in real multiplex networks. Nature Physics 12, 1076–1081 (2016).
Grady, D., Thiemann, C. & Brockmann, D. Robust classification of salient links in complex networks. Nature Communications 3, 864 (2012).
Allard, A., Serrano, M. Á., García-Pérez, G. & Boguñá, M. The geometric nature of weights in real complex networks. Nature Communications 8, 14103 (2017).
Schellenberger, J., Park, J. O., Conrad, T. M. & Palsson, B. Ø. BiGG: a Biochemical Genetic and Genomic knowledgebase of large scale metabolic reconstructions. BMC Bioinformatics Data sets at: http://bigg.ucsd.edu/ (2010).
Serrano, M. Á., Boguñá, M. & Sagués, F. Uncovering the hidden geometry behind metabolic networks. Molecular biosystems (2011).
Claffy, K., Hyun, Y., Keys, K., Fomenkov, M. & Krioukov, D. Internet mapping: from art to science. IEEE Computer Society (2009).
García-Pérez, G., Boguñá, M., Allard, A. & Serrano, M. Á. The hidden hyperbolic geometry of international trade: World trade atlas 1870–2013. Scientific Reports 6 (2016).
Acknowledgements
This work was supported by a James S. McDonnell Foundation Scholar Award in Complex Systems, the Ministerio de Economía y Competitividad of Spain projects no. FIS2013-47282-C2-1-P and no. FIS2016-76830-C2-2-P (AEI/FEDER, UE), and the Generalitat de Catalunya grant no. 2014SGR608.
Author information
Authors and Affiliations
Contributions
E.O., M.S. and M.Á.S. contributed to the design and implementation of the research, to the analysis of the results, and to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ortiz, E., Starnini, M. & Serrano, M.Á. Navigability of temporal networks in hyperbolic space. Sci Rep 7, 15054 (2017). https://doi.org/10.1038/s41598-017-15041-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-15041-0
This article is cited by
-
Deep learning-based methods for natural hazard named entity recognition
Scientific Reports (2022)
-
Intelligent route discovery towards rushing attacks in ad hoc wireless networks
Journal of Ambient Intelligence and Humanized Computing (2022)
-
Hyperbolic mapping of human proximity networks
Scientific Reports (2020)
-
Reducing energy bill of data center via flexible partial execution
Journal of Ambient Intelligence and Humanized Computing (2018)
-
Geometric characterisation of disease modules
Applied Network Science (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
