
Abstract
Measurement-device-independent quantum key distribution (MDI-QKD) with the active decoy state method can remove all detector loopholes, and resist the imperfections of sources. But it may lead to side channel attacks and break the security of QKD system. In this paper, we apply the passive decoy state method to the MDI-QKD based on polarization encoding mode. Not only all attacks on detectors can be removed, but also the side channel attacks on sources can be overcome. We get that the MDI-QKD with our passive decoy state method can have a performance comparable to the protocol with the active decoy state method. To fit for the demand of practical application, we discuss intensity fluctuation in the security analysis of MDI-QKD protocol using passive decoy state method, and derive the key generation rate for our protocol with intensity fluctuation. It shows that intensity fluctuation has an adverse effect on the key generation rate which is non-negligible, especially in the case of small data size of total transmitting signals and long distance transmission. We give specific simulations on the relationship between intensity fluctuation and the key generation rate. Furthermore, the statistical fluctuation due to the finite length of data is also taken into account.
Similar content being viewed by others
Introduction
Quantum key distribution (QKD) has been widely studied in both theoretical and experimental aspects1,2,3 since its initial proposal4. QKD enables two distant parties (Alice and Bob) to share a key, which is secret from any eavesdropper (Eve). It has been proved to be unconditional secure theoretically5.
Due to the imperfections of devices, there is still a big gap between the theory and practice of QKD. Fortunately, Lo et al. proposed a measurement-device-independent quantum key distribution (MDI-QKD) protocol6 to exclude all the attacks on detectors, which has been experimentally demonstrated by several groups7,8,9. Recently, the decoy state method has been widely used in MDI-QKD9,10,11,12,13,14,15,16,17 to defeat the photon number splitting (PNS) attack18, 19 and guarantee the security against imperfect sources, such as weak coherent pulses sources (WCPS)20, 21. These approaches are all related to the active decoy state selection, which is based on the assumption that Eve can not distinguish decoy and signal states. But this assumption may not stand in real active decoy state experiments, for which it may open up to side channels attacks and even break the security of the system when one actively modulates the intensities of pulses22, 23. The passive decoy state method24,25,26,27,28 can reduce the side channel information in the decoy state preparation procedure. Different from the active decoy state method, the passive one only uses one intensity signal, and Alice passively chooses the signal state and the decoy state according to the response of Alice’s detector. The method in ref. 28 extended passive decoy state to practical unstable light sources, which promoted its application to practical QKD. Therefore, it is necessary to consider the MDI-QKD with a passive decoy state. This has been demonstrated with phase encoding mode in ref. 29. Due to the different advantages between phase encoding and polarization encoding in practical application, we will apply the passive decoy state in MDI-QKD with polarization encoding mode8, 9, 30, 31.
An important imperfect factor of photon sources is intensity fluctuation32. Due to unavoidable interference from environments, there should be deviation between the true value and the assumed value. The deviation rises and falls irregularly, which can be called intensity fluctuation. The intensity fluctuation in experiments will result in the irregular change of the photon number distribution, and bring a potential security loopholes to the practical QKD33. The WCPs used in the passive decoy state method also has the imperfection of intensity fluctuation34. Therefore, how intensity fluctuations influence the performance of passive decoy state MDI-QKD protocol should also not be ignored.
In this paper, we apply the passive decoy state method to the MDI-QKD protocol with polarization encoding mode. Alice and Bob use WCPs with random phases to passively generate signal states or decoy states. Not only all the attacks on detectors can be removed, but also the side channels attacks on sources can be avoided, which may be generated by active modulation of source intensities. We analyse the security of this protocol, and show that MDI-QKD protocol with our passive decoy state method can provide a performance comparable to the active decoy state method. In order to fit for the demand of practical application, we discuss intensity fluctuation for MDI-QKD using the passive decoy state method. And based on the the formulas of yield and error rate derived in our paper, we get the key generation rate for our protocol with intensity fluctuation. According to the total gain and the overall error rate derived in our paper, we give a numerical simulations for our result. It shows that intensity fluctuation has a non-negligible effect on the key rate of the passive decoy state MDI-QKD protocol, especially in the case of small data size of total transmitting signals and long distance transmission. We give specific simulations on the relationship between intensity fluctuation and the key generation rate. Moreover, the finite-size analysis of this protocol is also taken into account in our paper.
Results
Passive Decoy State MDI-QKD Model
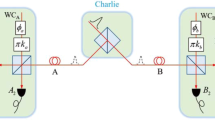
In this section, we apply the passive decoy state method to the MDI-QKD protocol, as shown in Fig. 1. The general process of this protocol is described as follows.

Passive decoy state MDI-QKD system model. WCP, weak coherent pulse; M, polarization modulators; BS, beam splitter; PBS, polarization BS; a 0, b 0, c h , c v , d h and d v , photon detector.
Alice generates phase-randomized pulses using two weak coherent sources with intensities μ 1 and μ 2, respectively. These two pulses interfere at a beam splitter (BS) with a transmittance of 50%; then there are two outcome signals which have the classically correlated photon number statistics. Alice passively generates signal or decoy states. The state Alice generated is a joint-distribution state according to the result of detector a 0. The detector a 0 with two modes c 0 and c 1. The letter c 0 indicates that the detector has no click and c 1 indicates the detector has a click. Thus corresponding to the detector’s modes, the output a has two modes, c 0 and c 1, which describe the signal state and decoy state, respectively. The total probability of having n photons in the output light can be written as
which is proven to be a non-Poissonian probability distribution33, and the parameters μ = μ 1 + μ 2, \(\alpha =\tfrac{\tfrac{\mu }{2}+{\xi }_{a}\,\cos \,{\theta }_{a}}{\mu }\), \({\xi }_{a}=\sqrt{{\mu }_{1}{\mu }_{2}}\) and \({\theta }_{a}={\varphi }_{{a}_{2}}-{\varphi }_{{a}_{1}}\) is the phase difference. The joint probability of having n photons in mode a and no click in the detector a 0 can be expressed by
\(\epsilon \) is the dark count rate of detector, and η d is the detector efficiency. The joint probability of having n photons in mode a and producing a click in the detector a 0 has now the form
Considering the normalization, the distributions of signal states and decoy states are respectively given by
where
is a normalization constant.
Bob performs the same process as Alice. He generates phase-randomized pulses using two weak coherent sources with intensities υ 1 and υ 2, respectively. The distributions expressions of signal state \({p}_{m,b}^{{c}_{0}}\) and decoy state \({p}_{m,b}^{{c}_{1}}\) are just like those in Eq. (3). It can be given by
where the parameters are corresponding to Alice’s.
The main step of MDI-QKD based on BB84 protocol and here we adopt the polarization encoding method6. Each of Alice and Bob prepares phase-randomized WCP in a different BB84 polarization state which is selected by means of a polarization modulator (M), independently and at random for each signal. Then they send them to an untrusted relay Charles (or Eve), who is supposed to perform a Bell-state measurement(BSM). Inside the measurement device, signals from Alice and Bob interfere at a 50:50 beam splitter (BS) that has a polarizing beam splitter (PBS) on each end. The PBS projecting the input photons into either horizontal (H) or vertical (V) polarization states. A successful Bell state measurement corresponds to the observation of precisely two detectors (associated to orthogonal polarizations) being triggered. Charles announces the results through a public channel to Alice and Bob. According to the result that Charles announces, Alice and Bob proceed on to basis reconciliation, error correction, and privacy amplification, as in traditional QKD protocols35. Then both Alice and Bob can ensure they have the same bits.
Estimation of the key generation rate
We modify the Gottesman-Lo-Lutkenhaus-Preskill (GLLP) formula36 according to the MDI-QKD security analysis. Then, we get the key generation rate formula,
where \({Y}_{11}^{Z}\) and \({e}_{11}^{X}\) are, respectively, the yield (the conditional probability that Charles declares a successful event) in the rectilinear (Z) basis and the error rate in the diagonal (X) basis, given that both Alice and Bob send single photon states; \({P}_{11}^{Z}\) denotes the probability distribution that both Alice and Bob send single photon states in the Z basis; f e ≥ 1 is the efficiency of the error correction protocol; H(x) = −x log 2 (x) − (1 − x) log 2 (1 − x)) is the binary Shannon entropy function; \({Q}_{{c}_{0}{c}_{0}}^{Z}\) and \({E}_{{c}_{0}{c}_{0}}^{Z}\) denote, respectively, the total gain and quantum bit error rate (QBER) of signal state in the Z basis. Here we use the Z basis for key generation and the X basis for testing only.
In a MDI-QKD implementation with the model described in our paper, we can obtain the total gains and error rates in both the X basis and the Z basis,
where λ ∈ {X, Z} denotes the basis choice and i, j = 0 or 1. \({Y}_{nm}^{\lambda }\) and \({e}_{nm}^{\lambda }\) are, respectively, the yield and error rate that Alice sends n photons pulse and Bob sends m photons pulse in the λ basis.
In practice, \({Q}_{{c}_{0}{c}_{0}}^{Z}\) and \({E}_{{c}_{0}{c}_{0}}^{Z}\) can be directly measured in experiments, while Alice and Bob only need to estimate the lower bound of the yield \({Y}_{11}^{Z}\) and the upper bound of the error rate \({e}_{11}^{X}\) using the decoy state methods. According to ref. 29, the lower bound of \({Y}_{11}^{\lambda }\) can be given
where λ = X or Z and the coefficients of the total gain in each mode are
and
The upper bound of \({e}_{11}^{\lambda }\) can be obtained with
The subscripts c 0 and c 1 denote Alice or Bob prepare a signal state and a decoy state, respectively. If a subscript 0 appears, then Alice or Bob prepares a vacuum state.
To analyse the security and performance of our passive decoy state MDI-QKD, we still need to know the total gains and the overall error rates in both the X basis and the Z basis. Supplementary Material shows the calculating process that how to get the total gain and overall error rate theoretically.
Passive Decoy State MDI-QKD With Intensity Fluctuation
We discuss an unavoidable imperfect factor, intensity fluctuation, in practice QKD protocol. We introduce parameter δ to denote the degree of intensity fluctuation. Here we take Alice as an example to describe the general process. The fluctuation ranges of the two intensities of Alice’s WCP sources are characterized by
where \({\delta }_{{\mu }_{1}}\) and \({\delta }_{{\mu }_{2}}\) are the variation ranges of μ 1 and μ 2, respectively. \({\mu }_{1}^{real}\) and \({\mu }_{2}^{real}\) are the real intensities of Alice’s WCP sources. We assume that the range of the intensity fluctuation parameters \({\delta }_{{\mu }_{1}}\) and \({\delta }_{{\mu }_{2}}\) is \([0,\,0.1]\) 34.
Similarly, we can get
where \({q}_{n,a}^{t,real}\) is the real total probability of having n photons in Alice’s output light, \({q}_{n,a}^{{c}_{0},real}\) and \({q}_{n,a}^{{c}_{1},real}\) are the joint probability of having n photons in mode a and no click or a click in the detector a 0, respectively. The capital letter L and U represent the lower and the upper bounds.
Due to the intensity fluctuation, we can derive the following expressions:
Then, we have
where
Bob has the same process as Alice. Next, we will calculate the lower bound of \({Q}_{11}^{{c}_{0}{c}_{0}}\) and \({Q}_{11}^{{c}_{1}{c}_{1}}\), i.e., \({Q}_{11}^{{c}_{0}{c}_{0},L}\) and \({Q}_{11}^{{c}_{1}{c}_{1},L}\), the upper bound of e 11, i.e., \({e}_{11}^{U}\), when we consider the intensity fluctuation.
The overall gain of Alice’s and Bob’s detector both producing a click is \({Q}_{{c}_{1}{c}_{1}}\) and no click is \({Q}_{{c}_{0}{c}_{0}}\). They can be expressed as
where the parameters are in the condition of using \({\mu }_{1}^{real}\), \({\mu }_{2}^{real}\), \({\upsilon }_{1}^{real}\) and \({\upsilon }_{1}^{real}\).
Then, applying \({Q}_{{c}_{1}{c}_{1}}-{Q}_{{c}_{0}{c}_{0}}\), we can get
The common point between the passive decoy state and the active decoy state is that the counting rates and the error rates of pulse of the same photon number states from the signal states and the decoy states shall be equal to each other37. Thus, in our study, we assume they are still equal to each other in the case of intensity fluctuation. Then, we use the following inequalities to substitute the elements in Eq. (19):
And note that \(n\geqslant 1\), we have \({q}_{n,a}^{{c}_{1},L}/{q}_{n,a}^{{c}_{0},U}\leqslant {q}_{\mathrm{1,}a}^{{c}_{1},L}/{q}_{\mathrm{1,}a}^{{c}_{0},U}\) and \({q}_{m,b}^{{c}_{1},U}/{q}_{m,b}^{{c}_{0},L}\leqslant {q}_{\mathrm{1,}b}^{{c}_{1},U}/{q}_{\mathrm{1,}b}^{{c}_{0},L}\). By using this inequalities, the elements in Eq. (19) can be substituted as:
Finally, we obtain the lower bound of \({Q}_{11}^{{c}_{1}{c}_{1}}\),
We can get
Then, we will calculate the upper bound of e 11. The overall quantum bit error rate (QBER) is
we can obtain the upper bound of e 11
The key generation rate with intensity fluctuation is
Statistical Fluctuation
In practical, the number of key distribution is finite, which will bring some statistical fluctuation into the parameter estimation. In this section, we will discuss the effect of the finite size on the security of MDI-QKD with our passive decoy state method based on the standard statistical analysis38, 39.
When consider the statistical fluctuation, the total gain \({Q}_{{c}_{i}{c}_{j}}^{\lambda }\) and the overall error rate \({E}_{{c}_{i}{c}_{j}}^{\lambda }\) are turned from determined values into intervals, which can be written as
where
Here σ α is the number of standard deviations, which is related to the failure probability of the security analysis. we choose σ α = 5, which means the failure probability is 5.73 × 107. These parameters used in our method are the same as those in the refs 12 and 29. \({N}_{{c}_{i}{c}_{j}}^{\lambda }\) is the length of data in the situation that Alice has the c i mode and Bob has the c j mode, where i,j = 0 or 1. Thus, the lower bound of \({Y}_{11}^{\lambda }\) and the upper bound of \({e}_{11}^{\lambda }\) given by Eqs (9) and (12), respectively, can be modified to ref. 29
We can also modify the lower bound of \({Q}_{11}^{{c}_{1}{c}_{1}}\) and the upper bound of \({e}_{11}^{\lambda }\) given by Eqs (22) and (25), respectively, as follows
Substituting Eqs (29) and (30) into Eqs (7), (31) and (32) into Eq. (26), we can respectively estimate the key generation rate with or without intensity fluctuation in the case of finite resource in different data length. In our method, we assume that Alice’s and Bob’s data length are the same for each pair of intensities.
Numerical Simulation
From our security analysis, we can obtain the yield \({Y}_{11}^{Z}\) and the error rate \({e}_{11}^{X}\), respectively, when Alice and Bob send single-photon pulses to Charles, as well as the total gains and the overall error rates in both the X basis and the Z basis. Then, we can get the key generation rate plotted in Fig. 2. The practical parameters for numerical simulations used in our method are η d = 14.5%, e d = 1.5%, Y 0 = 3 × 10−6, f e = 1.16 and α = 0.2 dB/km. These experimental parameters, including the detection efficiency η d , the total misalignment error e d and the background rate Y 0, are from the 144 km QKD experiment reported in ref. 40. Since two PDs (Photon Detectors) are used in ref. 40, the background rate of each PD here is roughly a quarter of the value there. We assume our model that the six PDs in MDI-QKD (see Fig. 1) have identical η d and Y 0.

Key generation rate versus the total transmission distance with the passive decoy state method based on polarization encoding mode (red solid line) compared to the passive decoy state method based on phase encoding mode (red dot-dashed line; ref. 29), the active decoy state method using two decoy states (blue dot-dashed line; ref. 12), and recently optimal active decoy state method (blue solid line; ref. 17).
In Fig. 2, we compare the key generation rate of MDI-QKD given by our passive decoy state method with that given by an active decoy state method with two decoy states in ref. 12 and recently optimal active decoy state method in ref. 17. The key generation rate is maximized by optimizing the intensity of sources. It can clearly be seen that the passive decoy state method can provide a performance comparable to the active one. We also compare the key generation rate of MDI-QKD given by our passive decoy state method which based on polarization encoding mode with that based on phase encoding mode in ref. 29, due to these two encoding modes are both applied in practical systems.
In addition, we will characterize the relationship between the key generation rate and the intensity fluctuation when transmission distance d is fixed. The result is shown in Fig. 3. Define R(δ)/R(0) as the fidelity of the the key generation rate with passive decoy state method, where R(δ) denotes the the key generation rate R with intensity fluctuation and R(0) denotes the the key generation rate R with no intensity fluctuation. From Fig. 3, we can see that the R(δ)/R(0) is getting to 0 with δ getting to 0.1. It indicates that when intensity fluctuation increases, the fidelity decreases, so does the key generation rate. Furthermore, we can also get that the effect of intensity fluctuation on the key generation rate monotonously increases with the increase of the transmission distance. So when we analyse the performance of MDI-QKD, the influence of intensity fluctuation can not be neglected, especially over long-distance communications.

The fidelity of the the key generation rate R(δ)/R(0) versus intensity fluctuation δ.
Figure 4 shows the key generation rate of MDI-QKD given by our passive-decoy-state method with different intensity fluctuation. We can find that intensity fluctuation obviously limit the secret key rate. In order to further study the effect of intensity fluctuation for different total numbers of transmitting signals N, we show the relations between R(δ)/R(0) and the secure transmission distance given that the intensity fluctuation is fixed to be 0.05 in Fig. 5. We can find that the smaller the data size of total transmitting signals is, more obvious the effect of intensity fluctuation is.

Secret key rate R versus the transmission distance with δ = 0.01,0.05,0.09,0.1 (curves from right to left).

Secret key rate R versus the transmission distance for δ = 0.05 and N = 1 × 10x with x = 9,10,11,12,13 (curves from left to right).
Discussion
In conclusion, we applied the passive decoy state method in the MDI-QKD based on polarization encoding mode, and gave a security analysis of this protocol. Using the passive decoy state method, not only all detector side channel attacks can be removed, but also side channel attacks on the sources can be overcome, which the active source modulation method may bring. We analysed the security of this protocol, and found that the MDI-QKD with our passive decoy state method can have a performance comparable to the protocol with the active decoy state method and the passive decoy state method based on phase encoding mode. To fit for the demand of practical application, we discuss intensity fluctuation in the security analysis of passive decoy state MDI-QKD protocol. In this case, we got the key generation rate through the formulas of yield and error rate derived in our paper. Based on the total gain and the overall error rate derived in our paper, we gave numerical simulations for our protocol. We showed that intensity fluctuation has a non-negligible effect on the secret key rate of the passive decoy state MDI-QKD protocol, especially in the case of small data size of total transmitting signals and long distance transmission. In addition, our analysis of statistical fluctuation shows that the finite-size effect also limits the key generation rate of MDI-QKD with passive decoy state method.
References
Gisin, N., Ribordy, G., Tittel, W. & Zbinden, H. Quantum cryptography. Rev. Mod. Phys. 74, 145–195 (2002).
Lo, H. K. & Chau, H. F. Unconditional security of quantum key distribution over arbitrarily long distances. Science 283, 2050 (1999).
Scarani, V., Acin, A., Ribordy, G. & Gisin, N. Quantum cryptography protocols robust against photon number splitting attacks for weak laser pulse implementations. Phys. Rev. Lett. 92, 057901 (2004).
Bennett, C. H. & Brassard. G. Quantum cryptography: public-key distribution and coin tossing. In Proceedings of IEEE International Conference on Computers Systems and Signal Processing 175–179 (1984).
Shor, P. W. & Preskill, J. Simple proof of security of the BB84 quantum key distribution protocol. Phys. Rev. Lett. 85, 441 (2000).
Lo, H. K., Curty, M. & Qi, B. Measurement-device-independent quantum key distribution. Phys. Rev. Lett. 108, 130503 (2012).
Liu, Y. et al. Experimental Measurement-Device-Independent Quantum Key Distribution. Phys. Rev. Lett. 111, 130502 (2013).
Tang, Z. Y. et al. Experimental Demonstration of Polarization Encoding Measurement-Device-Independent Quantum Key Distribution. Phys. Rev. Lett. 112, 190503 (2014).
Rubenok, A., Slater, J. A., Chan, P., Lucio-Martinez, I. & Tittel, W. Real-World Two-Photon Interference and Proof-of-Principle Quantum Key Distribution Immune to Detector Attacks. Phys. Rev. Lett. 111, 130501 (2013).
Ma, X. F. & Razavi, M. Alternative schemes for measurement-device-independent quantum key distribution. Phys. Rev. A 86, 062319 (2012).
Song, T. T., Wen, Q. Y., Guo, F. Z. & Tan, X. Q. Finite-key analysis for measurement-device-independent quantum key distribution. Phys. Rev. A 86, 022332 (2012).
Sun, S. H., Gao, M., Li, C. Y. & Liang, L. M. Practical decoy-state measurement-device-independent quantum key distribution. Phys. Rev. A 87, 052329 (2013).
Xu, F., Xu, H. & Lo, H. K. Protocol choice and parameter optimization in decoy-state measurement-device-independent quantum key distribution. Phys. Rev. A 89, 052333 (2014).
Zhou, C. et al. Biased decoy-state measurement-device-independent quantum key distribution with finite resources. Phys. Rev. A 91, 022313 (2015).
Wang, X. B. Three-intensity decoy-state method for device-independent quantum key distribution with basis-dependent errors. Phys. Rev. A 87, 012320 (2013).
Yu, Z. W., Zhou, Y. H. & Wang, X. B. Three-intensity decoy-state method for measurement-device-independent quantum key distribution. Phys. Rev. A 88, 062339 (2013).
Zhou, Y. H., Yu, Z. W. & Wang, X. B. Making the decoy-state measurement-device-independent quantum key distribution practically useful. Phys. Rev. A 93, 042324 (2016).
Lin, S., Wen, Q. Y., Gao, F. & Zhu, F. C. Eavesdropping on secure deterministic communication with qubits through photon-number-splitting attacks. Phys. Rev. A 79, 054303 (2009).
Brassard, G., Lütkenhaus, N., Mor, T. & Sanders, B. C. Limitations on practical quantum cryptography. Phys. Rev. Lett. 85, 1330 (2000).
Wang, X. B. Beating the photon-number-splitting attack in practical quantum cryptography. Phys. Rev. Lett. 94, 230503 (2005).
Song, T. T., Zhang, J., Qin, S. J., Gao, F. & Wen, Q. Y. Finite-key analyses for quantum key distribution with decoy-states. Quant. Inf. Comp. 11, 374–389 (2011).
Jiang, M. S., Sun, S. H., Li, C. Y. & Liang, L. M. Wavelength-selected photon-number-splitting attack against plug-and-play quantum key distribution systems with decoy states. Phys. Rev. A 86, 032310 (2012).
Ma, X. F. & Lo, H. K. Quantum key distribution with triggering parametric down-conversion sources. New J. Phys. 10, 073018 (2008).
Curty, M., Moroder, T., Ma, X. & Lütkenhaus, N. Non-Poissonian statistics from Poissonian light sources with application to passive decoy state quantum key distribution. Opt. Lett. 34, 3238 (2009).
Curty, M., Ma, X. F., Qi, B. & Moroder, T. Passive decoy-state quantum key distribution with practical light sources. Phys. Rev. A 81, 022310 (2010).
Mauerer, W. & Silberhorn, C. Quantum key distribution with passive decoy state selection. Phys. Rev. A 75, 050305(R) (2007).
Adachi, Y., Yamamoto, T., Koashi, M. & Imoto, N. Simple and efficient quantum key distribution with parametric down-conversion. Phys. Rev. Lett. 99, 180503 (2007).
Song, T. T., Qin, S. J., Wen, Q. Y., Wang, Y. K. & Jia, H. Y. Finite-key security analyses on passive decoy-state QKD protocols with different unstable sources. Scientific Reports 5, 15276 (2015).
Shan, Y. Z. et al. Measurement-device-independent quantum key distribution with a passive decoy-state method. Phys. Rev. A 90, 042334 (2014).
FerreiradaSilva, T. et al. Proof-of-principle demonstration of measurement-device-independent quantum key distribution using polarization qubits. Phys. Rev. A 88, 052303 (2013).
Xu, F., Curty, M., Qi, B. & Lo, H. K. Practical aspects of measurement-device-independent quantum key distribution. New J. Phys. 15, 113007 (2013).
Wang, S. et al. Decoy-state theory for the heralded single-photon source with intensity fluctuations. Phys. Rev. A 79, 062309 (2009).
Hu, J. Z. & Wang, X. B. Reexamination of the decoy-state quantum key distribution with an unstable source. Phys. Rev. A 82, 012331 (2010).
Li, Y., Bao, W. S., Li, H. W., Zhou, C. & Wang, Y. Passive decoy-state quantum key distribution using weak coherent pulses with intensity fluctuations. Phys. Rev. A 89, 032329 (2014).
Stucki, D., Gisin, N., Guinnard, O., Ribordy, G. & Zbinden, H. Quantum key distribution over 67 km with a plug & play system. New J. Phys. 4, 41 (2002).
Gottesman, D., Lo, H. K., Lütkenhaus, N. & Preskill, J. Security of quantum key distribution with imperfect devices. Quantum Inf. Comput. 4, 325 (2004).
Lo, H. K., Ma, X. F. & Chen, K. Decoy state quantum key distribution. Phys. Rev. Lett. 94, 230504 (2005).
Ma, X. F., Qi, B., Zhao, Y. & Lo, H. K. Practical decoy state for quantum key distribution. Phys. Rev. A 72, 012326 (2005).
Ma, X. F., Fung, C. & Razavi, M. Statistical fluctuation analysis for measurement-device-independent quantum key distribution. Phys. Rev. A 86, 052305 (2012).
Ursin, R. et al. Entanglement-based quantum communication over 144 km. Nat. Phys. 3, 481 (2007).
Acknowledgements
This work was supported by the National Natural Science Foundation of China, Grants No. 61572081, No. 61672110 and No. 61671082.
Author information
Authors and Affiliations
Contributions
L.L. proposed the theoretical method. L.L. and F.Z.G. wrote the main manuscript text. F.Z.G. and Q.Y.W. reviewed the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, L., Guo, FZ. & Wen, QY. Practical passive decoy state measurement-device-independent quantum key distribution with unstable sources. Sci Rep 7, 11370 (2017). https://doi.org/10.1038/s41598-017-09367-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-09367-y
This article is cited by
-
The Decoy-State Measurement-Device-Independent Quantum Key Distribution with Heralded Single-Photon Source
International Journal of Theoretical Physics (2020)
-
Practical covert quantum key distribution with decoy-state method
Quantum Information Processing (2019)
-
Passive measurement-device-independent quantum key distribution with orbital angular momentum and pulse position modulation
Optoelectronics Letters (2018)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
