
Abstract
Genome-wide disease-association mapping has been heralded as the study design of the next generation, but the lack of analytical methods to use genotype data fully is a large stumbling block. Here we describe an algorithm and statistical method that efficiently and exhaustively exploits haplotype information by subjecting alleles (a marker or contiguous sets of markers) from sliding windows of all sizes to transmission disequilibrium tests. By applying our method to simulated data and to Hirschsprung disease, we show that it can detect both common and rare disease variants of small effect. These results show that the theoretical benefits of genome-wide association studies are at last realizable.
Similar content being viewed by others


Main
Genome-wide linkage studies have been instrumental in elucidating the etiology of numerous single-gene diseases. For complex diseases, such as schizophrenia, autism and diabetes, these methods have proven less successful. In 1996, Risch and Merikangas1 established, on theoretic grounds, the increased power of association studies over linkage methods.
Risch and Merikangas argued that in an idealized future, disease-association studies could be carried out with substantial power by typing roughly 1 million functional single-nucleotide polymorphisms (SNPs; or perfect proxies) in the genome, the 'direct' method2. This future has still not arrived. The ability to assess the probable functional importance of genomic regions is improving3 but far from perfect. The alternative, to type all variants, is equally inviable, as there are estimated to be at least 15 million SNPs at frequency 1% or greater in the human genome4,5. Given that all SNP databases6,7,8,9 together contain fewer than 10 million unique SNPs, a substantial fraction of this variation has yet to be discovered and will not be characterized or have working experimental assays in the foreseeable future.
The HapMap project9, charged with characterizing human variation, has opted, for practical reasons, to focus on variants of frequency 5% or greater. Although by design some fraction of variants responsible for disease will be missed, genetic mapping studies incorporating the HapMap SNPs can still be useful because of linkage disequilibrium (LD) between a disease-causing mutation and a nearby typed site1. Testing individual SNPs for disease association may not, however, make full use of the genotype data set. Seeking association of combinations of SNPs that are inherited together with the disease-causing mutation (i.e., using haplotypes; the 'indirect' method2) may be more powerful.
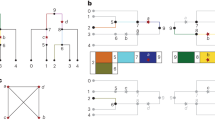
The most useful way of thinking about LD in the disease-mapping setting may not be as discrete blocks. An individual site may show greater LD over longer ranges than with surrounding sites10. This implies that a 'signal' for a disease-causing mutation may be optimally detected by testing the full length of a disease-associated haplotype for association (Fig. 1). In general, the beginning and end sites of a disease-associated haplotype are unknown, and they may be positioned irrespective of the boundaries of high LD blocks. Therefore, we tested allele windows of all positions and lengths.

(a) A region of the genome is characterized by three blocks of high LD, which have three, four and two haplotypes, respectively. The haplotypes are composed of common variants. (b) A disease-causing mutation, represented by an asterisk, occurs on an allele containing a particular haplotype from each block of high LD. Together, the haplotypes form a single disease-associated haplotype. (c) A depiction of case and control alleles assuming that the mutation is rare, the disease is recessive and the blocks are interrupted by recombinational hotspots. Comparing case and control haplotypes across the entire region (five versus zero) yields a greater signal than doing so within block 2 (five versus three). Although this depiction is simplified, it is the essential feature that allows common variants to detect rare mutations.
The challenge to our approach is one of multiple tests. Sliding windows of haplotypes are correlated. Many haplotypes are extremely rare and have little power to detect association a priori11. Bonferroni correction by the total number of tests results in vastly diminished power12. Moreover, carrying out statistical tests on all sliding windows is computationally intensive. There is no generally accepted methodology capable of handling genome-scale data to test hypotheses using a genome-wide significance level.
We report a new algorithm and associated computer implementation that exhaustively searches all alleles (here taken to mean individual SNPs as well as continuous haplotypes of all lengths) of input sequence data to find the set yielding the lowest transmission disequilibrium test (TDT) P values. These P values are then adjusted to multiple test–corrected genome-wide significance by permutation tests13. We call this method and implementation the exhaustive allelic TDT (EATDT). The computer implementation of EATDT is efficient, allowing it to achieve the high level of performance required for the permutation approach to multiple testing adjustment.
Results
Application to simulated sequences
Today, multiplex assays exist to genotype hundreds of thousands of SNPs in thousands of individuals14. To ascertain the extent to which exhaustive exploitation of observed haplotypes could compensate for genotyping at currently feasible densities, which are unlikely to include the disease-causing mutation, we ran a series of computer simulations. We generated 5-Mb sequences under the infinite sites neutral coalescent model4 with uniform recombination15. We formed diplotypes of individuals in families with these sequences and assigned disease status of family members using the mixed model of inheritance16. We selected trios in which the child was affected. We kept only the common sites whose frequencies were biased to reflect the distribution of variants found in public databases. We selected the final marker set at random to reach a density of 1 SNP per 10 kb. Diplotypes were phased by a computer algorithm and subjected to both an individual SNP association analysis and EATDT. Adjusted P values were considered significant at a genome-wide level of 0.05 using the Sidák method. We calculated power values for linkage assuming an affected sibling-pair design comprising 500 markers with a fully informative one closely linked (recombination fraction = 0) to the disease-associated locus, as in Risch and Merikangas1.
The data in Table 1 show that indirect, genome-wide association studies, carried out today with randomly selected common markers from public databases, will be able to uncover mutations with effects that are undetectable by linkage. The differences are most pronounced for mutations with moderate to small effects (genotype risk ratio γ = 3 or 2) and will be greater in real studies because a fully informative marker will rarely be tightly linked to the disease-causing mutation in a linkage design. Neither method has high power for detecting mutations with miniscule effects (γ = 1.5). Nor does the direct method in Risch and Merikangas1. Table 1 also shows that EATDT achieves a substantial increase in power over individual SNP analysis for many of the disease models considered. That this observation is especially true for rare disease-causing mutations is consistent with the notion that rare alleles are generally more recent and have had less time for recombination events and mutations to degrade surrounding patterns of LD17,18.
Because we used the permutation approach to multiple tests, the gains from considering haplotypes in our exhaustive allelic method are not overshadowed by the penalty paid for doing far more tests, as some researchers have worried19. There is, of course, a substantial computational load, but not an insurmountable one. A genome-wide data set of 2,000 trios genotyped at a density of 1 SNP per 10 kb takes ∼20 d to analyze on a single-processor personal computer. With a modestly sized cluster of computers, a whole-genome association analysis takes no longer than a weekend to complete.
We found that alleles with genome-wide significance for disease association were fairly predictive of chromosomes carrying disease-causing mutations (Table 2) and the general locations of these causal variants (Table 3). Accurate identification of chromosomal regions carrying mutations allows genetic dissection of loci at which multiple, distinct disease-causing alleles exist, a situation shown to be plausible by simulations10. (Of course, the alleles must each be of sufficient effect.)
We found that in a substantial fraction of simulations, the disease-associated haplotype yielding the lowest P value did not precisely localize the disease-causing mutation (Table 3). This finding is not unexpected because the most informative alleles are not necessarily the ones closest to the disease-causing mutation20. Other methodologies exist specifically to identify mutation location in the context of fine mapping21,22,23,24. Often, these algorithms assume that there is a single disease-causing mutation at a given locus or are unsuitable for genome-wide analysis because of their computational burden. In such cases, our method may be used to isolate distinct sets of chromosomes and specific regions containing disease-associated alleles, which may then be amenable to analysis by the location algorithms.
Application to Hirschsprung disease samples
We ran the power calculations for different SNP densities ranging from 1 SNP per 6 kb to 1 SNP per 300 kb. The power decreased gradually and was able to detect mutations of certain frequencies and effects, even at the lowest SNP density (data not shown). Encouraged by these findings and to see how well our theoretical results would hold for real data, we applied our methods to a data set comprising 35 trios with Hirschsprung disease (HSCR) from the Old Order Mennonite community25. The genome-wide scan consisted of 4,244 SNPs typed using the WGSA-EcoRI-p502 array (Affymetrix).
Analysis by EATDT identified three loci with genome-wide significance (Table 4). Two markers ∼1 Mb away from the disease-causing mutation in EDNRB resulting in the amino acid substitution W276C (ref. 26) yielded the lowest P values, which were equivalent whether the markers were taken singly or together (note that the disease-causing mutation was not in the genome scan). Two other markers in the genotype set were closer to the known disease-causing mutation, but one of the significant SNPs was 90 bp away from the marker closest to the disease-causing mutation. The genotyped markers in this data set were not evenly spaced. No haplotype obtained a P value any lower than the individual P values of the two significant SNPs.
The second locus of genome-wide significance corresponded to an eight-marker haplotype spanning 4 Mb on chromosome 21q21. This region contains a single annotated gene, NCAM2 (encoding neural cell adhesion molecule 2); this is notable because HSCR is a neurocristopathy. The location of the region on chromosome 21 is also notable, given the association between Down syndrome and HSCR27. The single-SNP analysis missed this locus entirely; the individual SNPs of that region yielded adjusted P values of >0.80.
The third locus of genome-wide significance was a four-marker haplotype covering 1.6 Mb on chromosome 10q21. This region is located 12 Mb telomeric of the gene RET on 10q11 previously reported to be mutated in HSCR disease28,29. Whether the positive signal corresponds to RET or another gene nearby warrants further scientific investigation. Like EDNRB, the locus could have been found without using haplotypes, given this specific data set. There were no markers in the genome scan within RET; the closest was 1 Mb away. Application of our computational method using markers specific to the region yielded findings that were significant on a single–candidate gene level but not on a genome-wide level (data not shown). EATDT should work just as well for SNPs typed for fine mapping and candidate gene approaches as for genome-wide studies.
Discussion
The power calculations from the simulations are not perfectly realistic but are probably underestimates. First, the Sidák method used to determine genome-wide significance was conservative because it treated the genome as 560 independent 5-Mb sequences. Of course, adjacent sequences are correlated and ideally should not be penalized as separate tests in P value adjustments. The underestimation of power, though, is probably not substantial because treating the genome as 2,800 independent 1-Mb sequences yielded values only slightly lower than those shown in Table 1 (data not shown). Second, the genotype sets used did not involve choosing an optimally informative set of markers, called tag SNPs9. This additional step would yield results equal to or better than those from the simple, random SNP selection scheme that we used. Perhaps most importantly, the underlying allele frequency spectrum was assumed to be well approximated by a neutral model with uniform recombination. We know the recombination assumption is not correct in detail30, and the neutral model's applicability to disease-associated loci, which are presumably under some degree of selection, is unproven12. Nevertheless, the coalescent simulation assuming constant population leads to conservative power estimates. Had a population expansion, as is presumed to have occurred in the ancestral history of humans, been modeled, LD would have extended over greater stretches. In such a scenario, on the other hand, the rough location capabilities of our method as demonstrated in the data shown in Table 3 would be less precise.
The signals captured by our exhaustive allelic approach in the trios with HSCR were found to be a superset of those detected by individual SNP analysis, consistent with our conclusion from simulations that our method exploiting LD is as powerful as, or more powerful than, single-SNP methods. The three loci identified by our method are largely concordant with earlier work by Puffenberger and colleagues26,31 using identity-by-descent analyses and LD mapping on microsatellite markers from a superset of the trios used in this report. The biggest difference is that evidence for association involving loci on 21q and 10q in this report was statistically significant after genome-wide adjustment for multiple tests. (EDNRB was judged significant in both studies.)
In our analysis of HSCR trios, genotyping error and missing data were handled during phase reconstruction with hap2 (ref. 32). The program checks for mendelian inconsistencies, which are recoded as missing data, and all missing data are then inferred. This inference process is generally accurate, but not perfect. The exact impact of extremely high error rates or large amounts of missing data in the context of EATDT is unknown and will require further research.
Our methodology solves several problems confronting the analysis of association studies. When an association study genotypes multiple SNPs, multiple test correction of P values is often missing or obscure. When the study simultaneously tests an unspecified number of haplotypes with unknown correlation, this problem becomes much worse. Here we show that a study can test every SNP and every haplotype in every sliding window of every size. In doing so, the study will incur a multiple test penalty. By assessing that penalty in a permutation framework, however, we show that the additional information gained by testing all alleles overcomes the penalty paid for the additional tests. These concepts and results are consistent with previous work33, which tested for interactions between all alleles, albeit on data sets with no more than eight SNPs. Although we tested only contiguous sets of SNPs, our method is more powerful than current genome-wide approaches and provides a computer implementation that is efficient and runs easily on large genome-wide data sets.
Most importantly, our method largely defuses the debate over the genetic basis of complex traits embodied by the common disease–common variant2,34,35 and common disease–rare variant viewpoints10,36. Many researchers in the field previously believed that adoption of one philosophy or the other had large implications for study design and analysis. Specifically, there was doubt that a rare disease variant could be detected by typing common SNPs. We show that such concerns may be unwarranted. Because rare mutations are, on average, younger than the surrounding SNPs, they often exist on long haplotypes spanning multiple blocks of high LD. We can therefore use long haplotypes to find rare mutations and use short haplotypes, or even individual SNPs, to find common mutations. Because EATDT tests both, we simultaneously investigate both potential genetic architectures.
The study design and analysis adopted in our simulations are not optimally efficient. They do not use a priori knowledge of the LD structure of the genome: SNPs are picked at random. They make no a priori assumptions about the potential functional importance of genomic regions. Incorporating such information could only improve power. But the 'prior-free' approach of the indirect method ensures its ability to make new, unexpected discoveries. The rationale behind the design of the HapMap project centers on the premise that only after the genetic basis of most complex diseases is understood can we truly know which SNPs are functional.
The genetics community has so far been reluctant to generate data at the magnitude we simulated. The HSCR data set that we analyzed is 1,000 times smaller than any of the simulations. But we found that even with current capabilities for genotyping and without further development of choosing tag SNPs, association studies using EATDT are very powerful. These findings should encourage investigators to go forward with large-scale genome-wide association studies, using the results of the HapMap project, to definitively elucidate complex diseases.
Methods
EATDT Algorithm.
For any given window, there were several distinct alleles. For each allele of a window, we created a bit word of 2n positions. If individual i (i = 1..n) was heterozygous with respect to the allele at hand and that allele was transmitted to an affected offspring, then the 2i–1th position was set to one; if that allele was not transmitted, then the 2ith position was set to one. All other digits of the bit word were left zero.
We determined the bit words of all window positions and lengths of the given set of alleles. We call the set of such words Y. A particular element y ∈ Y may have more than one corresponding allele (either SNP or haplotype). The sum of the bits of y gives b + c in a TDT table (Table 5) for the bit word's corresponding allele(s).
To obtain b, we constructed a 2n bitword, called ts, in which the odd positions were one and the even positions were zero. The odd bits of ts represent transmitted alleles. To find b, we applied a bitwise AND operation between y and ts; the sum of the bits of this operation is b. With b (and thereby c, as b + c is known), the P value from McNemar's test may be computed (exact calculations are stored in a lookup table). We calculated the P value for each element of Y. In this manner, we carried out TDTs on all possible alleles (SNPs and haplotypes of every size) in a given set of sequences and identified the allele(s) with the lowest TDT P value(s).
Suppose p is the lowest P value yielded by the algorithm, which was derived from a complicated probability density, which is dependent on the various steps outlined above and likely to be without closed form. To find the true statistical significance of p, we carried out a permutation test. For NN iterations, we constructed the kth permutation of the original data by creating a random bitword tsk . We set the odd number bits, denoted tsk,i (i = 1,3,5...), equal to one with probability 0.5 and zero otherwise. We set the even number bits, i + 1, denoted tsk,i+1, equal to ∼tsk,i, where ∼ is the logical not. In this way, the transmitted and untransmitted status for each pair of alleles is randomized. For any given permutation, for all y ∈ Y, we carried out a bitwise AND operation between y and tsk , thereby obtaining the b and c values for this haplotype and this permutation. Let pk be the lowest P value observed in the kth permutation. The adjusted P value of our procedure is the number pk (k = 1..NN) smaller than p, divided by NN. An example and more detailed explanation of our algorithm is included in Supplementary Methods online.
Simulations.
We simulated nucleotide sequences from an infinite sites37 model with recombination38. Because we were working with extremely large regions, we reimplemented the classical Hudson algorithm with several computational improvements, including rewriting naturally recursive routines in a nonrecursive fashion, efficient searches for regions experiencing most recent common ancestor events and special procedures for careful management of memory storage. These enhancements allowed us to simulate the 'whole' effective human population of 40,000 alleles for sequences parameterized by θ = 4,000 (nucleotide diversity) and 4Nr = 2,000 (N is the effective population size; r, the recombination rate per individual per generation). Assuming that θ per site is 8 × 10−4 (ref. 39), N is the traditional 10,000 and r = 30 exchanges per 3 × 109 bp per meiosis, the values of θ and 4Nr correspond to sequence variation and recombination found in 5 Mb of sequence. We formed an individual's diplotype by choosing two sequences with replacement from the 40,000 haplotypes (thereby maintaining Hardy-Weinberg equilibrium). We randomly paired individuals to form couples, to which offspring were assigned in accordance to the Poisson distribution (mean = 2) under independent assortment of haplotypes.
Our version of the mixed model of inheritance follows16,40. For a dichotomous trait, the model assumes that the trait is due to an underlying, but unobservable, liability scale (y) to which mendelian inheritance of a single gene (l), multifactorial transmission (i.e., other genes; c) and random environmental effects (e) contribute additively and independently: y = l + c + e. Affectation status is defined by a threshold Z on the liability scale such that all individuals with a liability value above Z are considered affected. For parents, the variables c and e are random variables chosen from normal distributions with means zero and variances C and E, respectively, such that C + E = 1. The major locus has two alleles, G and g with the disease-associated allele g having frequency q. (In our simulations, the actual disease-causing mutation was chosen to be the most central site whose minor allele frequency was between q ± 0.2q.) The difference, in units of s.d., between the means of the liability distributions of the two homozygous classes is t; the degree of dominance is d. Therefore, l equals 0, td or t depending on whether the parent has genotype GG, Gg or gg at the major locus. For children, y is determined in the same way except c is obtained by summing the midparental (average of the two parental values) c value and a random number chosen from a normal distribution with mean zero and variance C/2.
In simulations of the mixed model of inheritance assuming C = E, a user must input q, t, d and Z or q, genotype risk ratio (GRR) and Z. (Note in the latter case, Z has no bearing on the impact of the disease-causing mutation. It merely influences the number of individuals who need to be simulated to acquire a given number of TDT trios.) The formal relationship between the mixed model parameters and GRR, as with sibling relative risk (λs ) and heritability (h2) is developed below.
GRR is the increased chance that an individual with a particular genotype will develop a given disease. Suppose the risk for individuals of genotype Gg is γ times greater than the risk for individuals with genotype GG: GRR = γ. Under a multiplicative assumption for two g alleles, the GRR for genotype gg is γ2. To clarify the relationship of these GRR parameters to the mixed model of inheritance, we first write out the disease prevalence using the latter's formalism:

where K is the prevalence, p is 1 − q and Φ is the cumulative distribution function of a standard normal distribution. Dividing equation 1 by the probability of disease given genotype gg, Φ (−Z + t), we obtain the following equation:

Simply, ( Φ(−Z)/Φ(−Z + t)) and (Φ(−Z + dt))/Φ(−Z + t)) are γ2 and γ, respectively. Given γ, λs easily follows. If this single locus were the only genetic contribution to disease (C = 0), λs would be the increased risk of developing a disease for a sibling of an affected individual over the population prevalence. If multiple loci contribute, the parameter (call it λas for the C > 0 case) is the increased risk attributable to this one locus. From Risch and Merikangas1,

Risch and Merikangas actually use K′ as prevalence throughout their 1996 paper, because the probability of disease given genotype gg cancels out of the final equations used to calculate power.
Finally, we may calculate h2, which, in the absence of other loci (C = 0) and for an additive locus (d = 1/2), is the narrow sense heritability of the trait, or the extent to which liability is determined by the additive effects of genes transmitted from parents to offspring. In the presence of other genetic loci, the parameter (call it h2a ) can be interpreted as the proportion of phenotypic variance explained by the additive effects of this locus. From Falconer & Mackay (ref. 41), we have the equation

where m is the mean deviation of the liability of the general population, mS is the mean deviation for siblings of affected individuals and i is the mean deviation of affected individuals from m. Substituting the parameters already derived into equation 3, we obtain the following equation:

where f is the probability density function of a standard normal distribution40.
Table 6 shows input and tabulated parameters related to the simulations underlying Tables 1,2,3,4. To derive the values in Table 6, for a given set of γ, q and Z and assuming C = E = 1/2, the above equations may be used to calculate analytically λas , t, d and K. We calculated h2a with C = 0 and E = 1/2. We derived λas , λs and h2 by tabulating the affected individuals among the simulated individuals and making appropriate calculations with information regarding family structures. The former value assumes a multiplicative model for the penetrance of unlinked loci42.
Because association studies in the future will use SNPs characterized in public databases, we simulated our marker sets to reflect the bias in allele frequency spectrum of SNPs from those databases. To do so, we assumed that an allele with derived allele frequency x in the general population was contained in the human SNP database dbSNP with probability p(x). To derive p(x), we noted that dbSNP was largely created by aligning random small reads (generally 500 bases or less) against the human genome. Assuming that the number of reads that align at any given SNP is Poisson-distributed (a reasonable assumption given the enormous size of the genome relative to the size of each individual read) with mean η, we calculated the probability that any given SNP with derived allele frequency x is contained in dbSNP as follows:

We chose sites consistent with the above frequency distribution and thinned the marker set by first dropping sites whose minor allele frequency was less than 0.2 and then dropping sites at random until the density was 1 SNP per 10 kb.
We selected TDT trios at random based on the affectation status of offspring up to a specified sample size. We derived multiple trios from multiplex sibships. We phased diplotypes using hap2 (ref. 32) at 10,000 iterations, with the first 5,000 discarded as 'burn-in' and the remainder thinned by storing every 20th iteration. We then subjected the phased trios to our exhaustive allelic algorithm and adjusted P values of the alleles for multiple tests by permutation tests comprised of 11,000 iterations. For a given allele, we increased the numerator and denominator of the corresponding adjusted P value by one (call the result p′) to account for Monte Carlo error43. Given the fact that hap2 may be modified to output a posterior distribution of haplotypes, strictly speaking, the P values should have been computed over these distributions rather than with a single realization of the phasing program. Given the high accuracy of haplotyping trios32 and the computational burden required by the former method, however, the latter procedure was adopted instead.
Because we simulated ∼5 Mb of contiguous sequence, we resorted to an analytical correction method to account for genome-scale multiple testing. As of human genome build 34, the total size of the sequenced human genome is ∼2,800 Mb. To account for the multiple tests from 2,800/5 other 5-Mb regions, we applied the Sidák correction44 to the p′ value to determine the final adjusted P value (call it p*): p* = 1 − (1 − p′)2,800/5.
We considered p* to be statistically significant at the nominal 0.05 value. The Sidák correction is conservative but slightly less so than the more popular Bonferroni method. As with the latter, the former treats each 5-Mb region as independent, which is not true for adjacent regions of the genome. We used analogous procedures for single-SNP analysis corrected by permutation tests.
Evidence that the permutation procedure of EATDT produces the proper type I error rate is given in Supplementary Figure 1 online.
Old Order Mennonite data.
We mapped the 4,244 SNPs of each member of the 35 trios onto build 34 of the human genome. We created bit words separately for each of the 22 autosomes, because creating bit words on the whole data set would have generated meaningless interchromosomal alleles. We aggregated the bit words and analyzed them as we analyzed the simulations. No post-permutation test adjustment (Sidák correction) was necessary. To break ties among alleles with the same P value, we reported any individual SNPs that existed. Otherwise, we chose the longest allele.
Note: Supplementary information is available on the Nature Genetics website.
References
Risch, N. & Merikangas, K. The future of genetic studies of complex human diseases. Science 273, 1516–1517 (1996).
Collins, F.S., Guyer, M.S. & Chakravarti, A. Variations on a theme: cataloging human DNA sequence variation. Science 278, 1580–1581 (1997).
Thomas, J.W. et al. Comparative analyses of multi-species sequences from targeted genomic regions. Nature 424, 788–793 (2003).
Watterson, G.A. On the number of segregating sites in genetical models without recombination. Theor. Popul. Biol. 7, 256–276 (1975).
Kruglyak, L. & Nickerson, D.A. Variation is the spice of life. Nat. Genet. 27, 234–236 (2001).
Sachidanandam, R. et al. A map of human genome sequence variation containing 1.42 million single nucleotide polymorphisms. Nature 409, 928–933 (2001).
Patil, N. et al. Blocks of limited haplotype diversity revealed by high-resolution scanning of human chromosome 21. Science 294, 1719–1723 (2001).
Venter, J.C. et al. The sequence of the human genome. Science 291, 1304–1351 (2001).
The International HapMap Consortium. The International HapMap Project. Nature 426, 789–796 (2003).
Pritchard, J.K. Are rare variants responsible for susceptibility to complex diseases? Am. J. Hum. Genet. 69, 124–137 (2001).
Chapman, J.M., Cooper, J.D., Todd, J.A. & Clayton, D.G. Detecting disease associations due to linkage disequilibrium using haplotype tags: a class of tests and the determinants of statistical power. Hum. Hered. 56, 18–31 (2003).
Long, A.D. & Langley, C.H. The power of association studies to detect the contribution of candidate genetic loci to variation in complex traits. Genome Res. 9, 720–731 (1999).
Churchill, G.A. & Doerge, R.W. Empirical threshold values for quantitative trait mapping. Genetics 138, 963–971 (1994).
Kennedy, G.C. et al. Large-scale genotyping of complex DNA. Nat. Biotechnol. 21, 1233–1237 (2003).
Hudson, R.R. Properties of a neutral allele model with intragenic recombination. Theor. Popul. Biol. 23, 183–201 (1983).
Morton, N.E. & MacLean, C.J. Analysis of family resemblance. 3. Complex segregation of quantitative traits. Am. J. Hum. Genet. 26, 489–503 (1974).
Hudson, R.R. The sampling distribution of linkage disequilibrium under an infinite allele model without selection. Genetics 109, 611–631 (1985).
de la Chapelle, A. & Wright, F.A. Linkage disequilibrium mapping in isolated populations: the example of Finland revisited. Proc. Natl. Acad. Sci. USA 95, 12416–12423 (1998).
Terwilliger, J.D. & Weiss, K.M. Linkage disequilibrium mapping of complex disease: fantasy or reality? Curr. Opin. Biotechnol. 9, 578–594 (1998).
Liang, K.Y., Hsu, F.C., Beaty, T.H. & Barnes, K.C. Multipoint linkage-disequilibrium-mapping approach based on the case-parent trio design. Am. J. Hum. Genet. 68, 937–950 (2001).
McPeek, M.S. & Strahs, A. Assessment of linkage disequilibrium by the decay of haplotype sharing, with application to fine-scale genetic mapping. Am. J. Hum. Genet. 65, 858–875 (1999).
Service, S.K., Lang, D.W., Freimer, N.B. & Sandkuijl, L.A. Linkage-disequilibrium mapping of disease genes by reconstruction of ancestral haplotypes in founder populations. Am. J. Hum. Genet. 64, 1728–1738 (1999).
Morris, A.P., Whittaker, J.C. & Balding, D.J. Bayesian fine-scale mapping of disease loci, by hidden Markov models. Am. J. Hum. Genet. 67, 155–169 (2000).
Liu, J.S., Sabatti, C., Teng, J., Keats, BJ. & Risch, N. Bayesian analysis of haplotypes for linkage disequilibrium mapping. Genome Res. 11, 1716–1724 (2001).
McCallion, A.S. et al. Genomic variation in multigenic traits: Hirschsprung disease. Cold Spring Harb. Symp. Quant. Biol. 68, 373–381 (2003).
Puffenberger, E.G. et al. Identity-by-descent and association mapping of a recessive gene for Hirschsprung disease on human chromosome 13q22. Hum. Mol. Genet. 3, 1217–1225 (1994).
Chakravarti, A. & Lyonnet, S. Hirschsprung disease. in The Metabolic and Molecular Bases of Inherited Disease (ed. Charles R.S.) (McGraw-Hill, New York, 2001).
Edery, P. et al. Mutations of the RET proto-oncogene in Hirschsprung's disease. Nature 367, 378–380 (1994).
Romeo, G. et al. Point mutations affecting the tyrosine kinase domain of the RET proto-oncogene in Hirschsprung's disease. Nature 367, 377–378 (1994).
Jeffreys, A.J., Kauppi, L. & Neumann, R. Intensely punctate meiotic recombination in the class II region of the major histocompatibility complex. Nat. Genet. 29, 217–222 (2001).
Puffenberger, E.G. et al. A missense mutation of the endothelin-B receptor gene in multigenic Hirschsprung's disease. Cell 79, 1257–1266 (1994).
Lin, S., Chakravarti, A. & Cutler, D.J. Haplotype and missing data inference in nuclear families. Genome Res. 14, 1624–1632 (2004).
Jannot, A.S., Essioux, L., Reese, M.G. & Clerget-Darpoux, F. Improved use of SNP information to detect the role of genes. Genet. Epidemiol. 25, 158–167 (2003).
Lander, E.S. & Schork, N.J. Genetic dissection of complex traits. Science 265, 2037–2048 (1994).
Lander, E.S. The new genomics: global views of biology. Science 274, 536–539 (1996).
Weiss, K.M. & Terwilliger, J.D. How many diseases does it take to map a gene with SNPs? Nat. Genet. 26, 151–157 (2000).
Watterson, G.A. On the number of segregating sites in genetic models without recombination. Theor. Popul. Biol. 7, 256–276 (1975).
Hudson, R.R. Properties of a neutral allele model with intragenic recombination. Theor. Popul. Biol. 23, 183–201 (1983).
Halushka, M.K. et al. Patterns of single-nucleotide polymorphisms in candidate genes for blood-pressure homeostasis. Nat. Genet. 22, 239–247 (1999).
Falconer, D.S. The inheritance of liability to certain diseases, estimated from the incidence among relatives. Ann. Hum. Genet. 29, 51–76 (1965).
Falconer, D.S. & Mackay, T.F.C. Introduction to Quantitative Genetics (Longman, Essex, 1996).
Risch, N. Assessing the role of HLA-linked and unlinked determinants of disease. Am. J. Hum. Genet. 40, 1–14 (1987).
Davison, A.C. & Hinkley, D.B. Bootstrap Methods and Their Application (Cambridge University Press, Cambridge, 1997).
Sidak, Z. Rectangular Confidence Regions for the Means of Multvariate Normal Distributions. J. Am. Stat. Assoc. 62, 626–633 (1967).
Acknowledgements
We thank K. Broman and D. Valle for their insightful comments and discussions regarding this work and J. Kloss and C. Kashuk for their technical assistance. S.L. is supported by the Medical Scientist Training Program and is a student of the Predoctoral Training Program in Human Genetics at Johns Hopkins School of Medicine. A.C. and D.J.C. are supported by project grants from the US National Institutes of Health.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Supplementary Figure 1
Null distribution. (PDF 8 kb)
Rights and permissions
About this article
Cite this article
Lin, S., Chakravarti, A. & Cutler, D. Exhaustive allelic transmission disequilibrium tests as a new approach to genome-wide association studies. Nat Genet 36, 1181–1188 (2004). https://doi.org/10.1038/ng1457
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/ng1457
This article is cited by
-
Fine Mapping on Chromosome 13q32–34 and Brain Expression Analysis Implicates MYO16 in Schizophrenia
Neuropsychopharmacology (2014)
-
Polymorphisms in the superoxidase dismutase genes reveal no association with human longevity in Germans: a case–control association study
Biogerontology (2013)
-
Common variants at SCN5A-SCN10A and HEY2 are associated with Brugada syndrome, a rare disease with high risk of sudden cardiac death
Nature Genetics (2013)
-
Four new loci associations discovered by pathway-based and network analyses of the genome-wide variability profile of Hirschsprung’s disease
Orphanet Journal of Rare Diseases (2012)
-
Convergent Evidence that Choline Acetyltransferase Gene Variation is Associated with Prospective Smoking Cessation and Nicotine Dependence
Neuropsychopharmacology (2010)
