- NEWS AND VIEWS
UK Biobank shares the promise of big data
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$29.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Rent or buy this article
Prices vary by article type
from$1.95
to$39.95
Prices may be subject to local taxes which are calculated during checkout
Nature 562, 194-195 (2018)
doi: https://doi.org/10.1038/d41586-018-06948-3
References
Evangelou, E. et al. Nature Genet. 50, 1412–1425 (2018).
Bycroft, C. et al. Nature 562, 203–209 (2018).
Elliott, L. T. et al. Nature 562, 210–216 (2018).
The Wellcome Trust Case Control Consortium. Nature 447, 661–678 (2007).
Moutsianas, L. & Gutierrez-Achury, J. Methods Mol. Biol. 1793, 111–134 (2018).
Hibar, D. P. et al. Nature 520, 224–229 (2015).
Fornage, M. et al. Ann. Neurol. 69, 928–939 (2011).
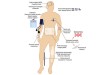 Read the paper: The UK Biobank resource with deep phenotyping and genomic data
Read the paper: The UK Biobank resource with deep phenotyping and genomic data
 Read the paper: Genome-wide association studies of brain imaging phenotypes in UK Biobank
Read the paper: Genome-wide association studies of brain imaging phenotypes in UK Biobank
 Cracking the regulatory code
Cracking the regulatory code
 A deep dive into genetic variation
A deep dive into genetic variation